(原文: https://gethue.com/self-service-impala-sql-query-troubleshooting/)
データ探検の皆さん!
私たちはImpalaクエリのパフォーマンス問題のデバッグに役立つ方法を探しています。この新機能は開発中のものであり、ご意見を参考にしてさらなる機能追加を目指しています。
カタログのデータを見つけてクエリアシスタントを使用した後、エンドユーザーはなぜクエリの実行に時間がかかるのかを不思議に思うかもしれません。Impala プロファイラー上に構築されているこの新機能は、エンドユーザーに学びを与え、より多くの情報を明らかにするので、エンドユーザー自身がより生産的になります。フローを紹介するシナリオは次の通りです。
実行タイムライン
新機能を体感するためにいくつかのクエリを実行します。
SELECT *
FROM
transactions1g s07 left JOIN transactions1g s08
ON ( s07.field_1 = s08.field_1) limit 100
transactions1g は 1GB のテーブルであり、述語のない自己結合はテーブル全体のネットワーク転送を矯正します。
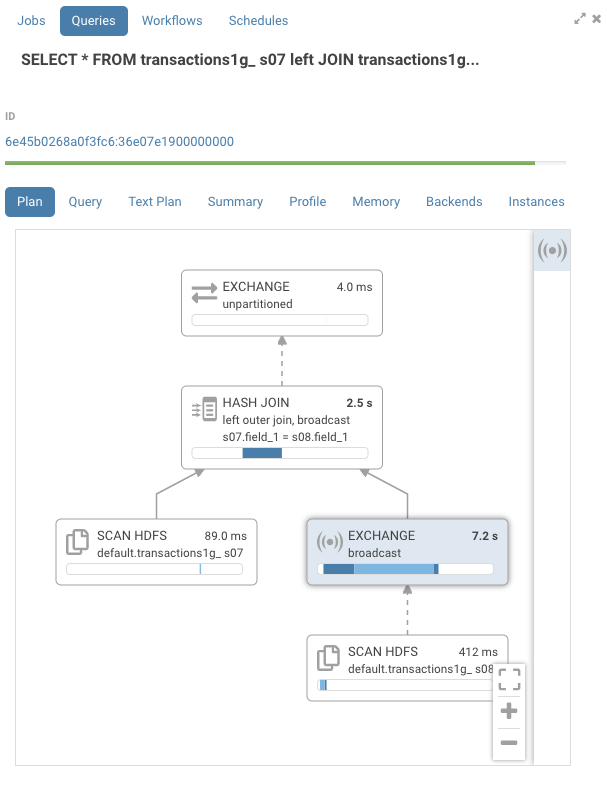
プロファイルを見ると、各ノードの右上にIOとCPU時間を表す数字が確認できます。実行中、そのノードがいつ処理されたかの推定が提供されるタイムラインもあります。濃い青色はCPU時間、薄い青色はネットワークまたはディスクIO時間です。この例では、ハッシュ結合に 2.5 秒実行されていることがわかります。2台のホスト間でデータを行う交換(EXCHANGE)ノードが最も高価なノードで、7.2 秒でした。
詳細ペイン
右側にはデフォルトでクローズされているペインがあります。ペインのヘッダを押して開く、または閉じます。そこでは実行時間でソートされた全てのノードがリストされます。これにより、より大きな実行グラフをナビゲートするのが簡単になります。このリストはクリック可能で、クリックにより適切なノードに移動します。
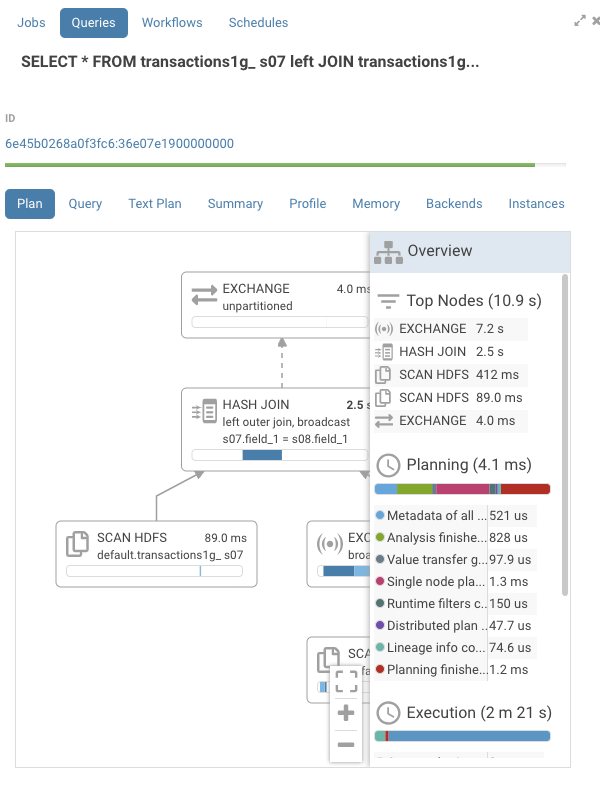
イベント
交換(EXCHANGE)ノードをクリックすると、もう少し詳細な実行タイムラインがわかります。
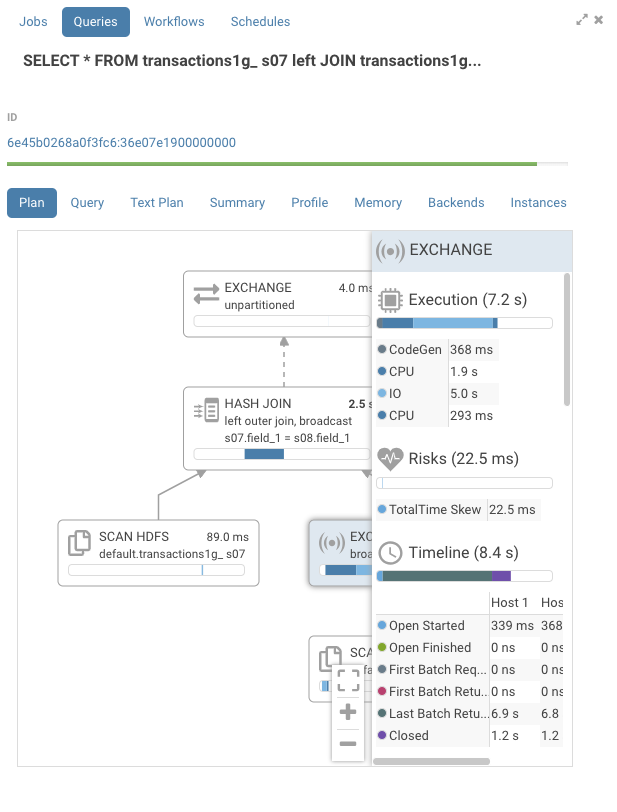
交換では、IOが最も高価な部分であったことがわかります。
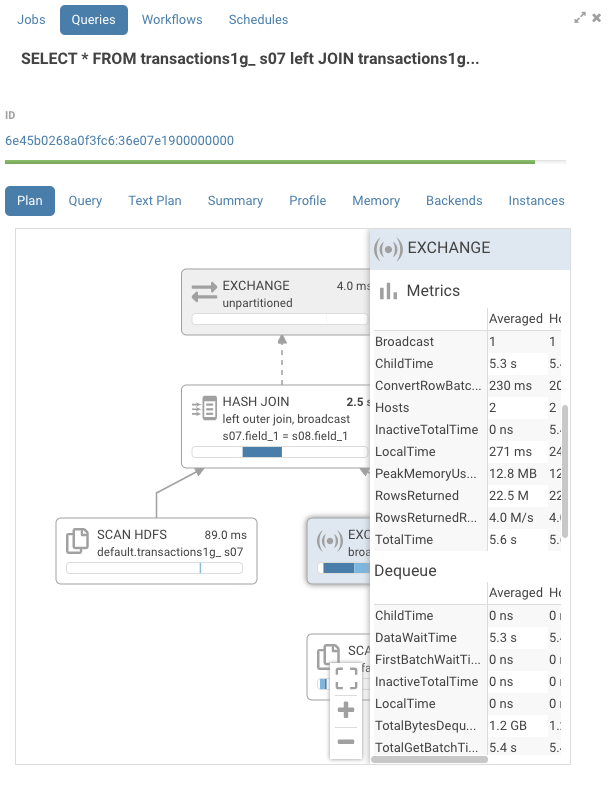
ホスト別の統計
詳細ペインには、メモリ消費とネットワーク転送速度のような、ホスト毎、ノード毎に集計された詳細の統計も含まれています。
リスク
詳細ペインには、ノード毎に「Risks」というセクションがあります。このセクションは、このオペレーターのパフォーマンスを向上させる方法についてのヒントを紹介します。現在、これはデフォルトで有効になっていません。有効にするには Hue.ini ファイルでこのフラグを設定します。
[notebook]
enable_query_analysis=true
CodeGen
いくつかのクエリと、識別可能なリスクについて見てみましょう。
SELECT s07.description, s07.salary, s08.salary,
s08.salary - s07.salary
FROM
sample_07 s07 left outer JOIN sample_08 s08
ON ( s07.code = s08.code)
where s07.salary > 100000
sample_07 & sample_08 are small sample tables that come with Hue.
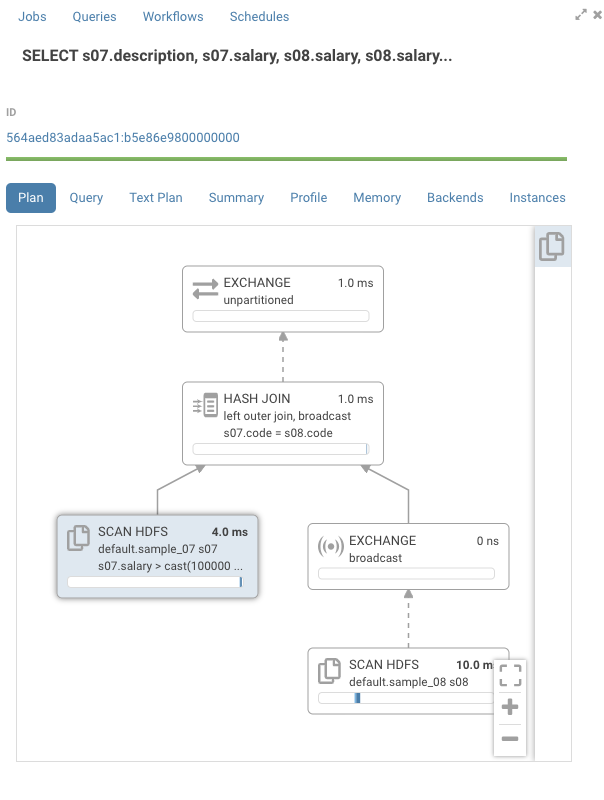
グラフを見ると、タイムラインはほとんどが空です。ノードの1つを開くと、全ての時間が「CodeGen」にかかっていることがわかります。
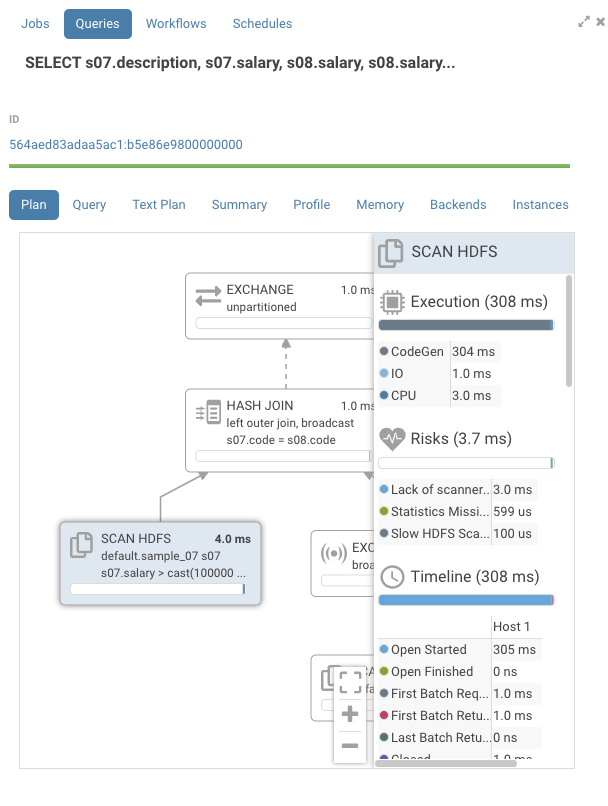
Impalaは、SQLの要求をネイティブコードにコンパイルして、グラフ中の各ノードで実行します。大きなテーブルを持つクエリでは、これによりパフォーマンスが大幅に向上します。小さなテーブルでは、CodeGen が実行時間の主な要因であることがわかります。通常 Impala は小さなサイズのテーブルでは CodeGen を無効にしますが、risks セクションで指摘されているように、Impala は「統計が欠けている(Statistics missing)」というステートメントにより小さなテーブルであることを知りません。ここでは2つの解決策があります。
- 欠けている統計を追加します。これを行う方法の1つは次のコマンドを実行することです。
compute stats sample_07; compute stats sample_08;
これは通常正しいやり方ですが、大きなテーブルでは非常に高価になる場合があります。</li>
* 次の方法でクエリの[codegenを無効化][9]します。 <pre><code class="bash">set DISABLE_CODEGEN=true
[<img class="aligncenter size-medium wp-image-5673" src="https://cdn.gethue.com/uploads/2019/03/Screen-Shot-2019-03-07-at-9.52.37-AM.png" alt="" width="460" height="600" />][10]
クエリを再実行した後は、CodeGen がなくなっていることがわかります。
### 結合の順序 {.p1}
結合(JOIN)ノードを開くと、結合順序が正しくない(Wrong Join order)という警告があります。
[<img class="aligncenter wp-image-5678" src="https://cdn.gethue.com/uploads/2019/03/Screen-Shot-2019-03-07-at-4.50.54-PM.png" alt="" width="460" height="600" />][11]
Impalaはグラフの[右側][12]に大きなサイズのテーブルがあることを好みますが、この場合は逆になっています。通常 Impala はこれを自動的に最適化しますが、結合されるテーブルの統計情報が欠落していることがわかりました。これを修正するにはいくつかの方法があります。
1. 前述のように不足している統計情報を追加します。
2. 結合の順序を変更するようにクエリを書き換えます。 <pre><code class="bash">SELECT s07.description, s07.salary, s08.salary,
s08.salary - s07.salary FROM sample_08 s08 left outer JOIN sample_07 s07 ON ( s07.code = s08.code) where s07.salary &gt; 100000
[<img class="aligncenter size-full wp-image-5674" src="https://cdn.gethue.com/uploads/2019/03/Screen-Shot-2019-03-07-at-9.57.14-AM.png" alt="" width="460" height="600" />][13]
警告がなくなり、結合の時間が短くなりました。
### スピル {.p1}
Impalaは十分なメモリがある場合、全てのオペレーターをメモリ内で実行します。実行がメモリに全て収まらない場合、Impalaは[利用可能なディスク][14]を使用して一時的にそのデータを保存します。これを実際に確認するには、以前と同じクエリを実行しますが、スピルをトリガーするように[メモリ制限][15]を設定します。
<pre><code class="bash">set MEM_LIMIT=1g;
select * FROM transactions1g s07 left JOIN transactions1g s08 ON ( s07.field_1 = s08.field_1);
[<img class="aligncenter wp-image-5676" src="https://cdn.gethue.com/uploads/2019/03/Screen-Shot-2019-03-07-at-11.40.24-AM.png" alt="" width="460" height="600" />][16]
結合ノードを見ると、risk セクションに、スピルしたパーティションに関するエントリがあることがわかります。通常結合にはCPU時間しかありませんが、この場合はスピルのためのIO時間もあります。
### Kuduのフィルタリング {.p1}
KuduはImpalaがサポートしているストレージバックエンドの一つです。Impalaは単独でさまざまなファイルデータフォーマットをクエリできますが、Impala on Kudu はデータの素早い更新と挿入を可能にし、小さなファイルが含まれている場合のより良い選択です。ImpalaをKuduで使用する場合、これらの間のデータ転送を減らすために、一部の操作をKuduにプッシュダウンします。しかし、KuduはImpalaがサポートする全ての[オペレーター][17]をサポートしているわけではありません。例えばこの記事の執筆時点では、Impalaは「Like」オペレーターをサポートしていますがKuduはサポートしていません。そのような場合、Kuduでネイティブにフィルタリングできない全てのデータはImpalaに転送されてフィルタリングされます。両者の動作の違いを見てみましょう。
<pre><code class="bash">SELECT * FROM transactions1g_kudu s07 left JOIN transactions1g_kudu s08 on s07.field_1 = s08.field_1
where s07.field_5 LIKE ‘2000-01%';
[<img class="aligncenter wp-image-5680" src="https://cdn.gethue.com/uploads/2019/03/Screen-Shot-2019-03-07-at-5.00.59-PM.png" alt="" width="460" height="600" />][18]
グラフを見ると、Kudu ノードには Kuduで費やされた IO 時間と Impala で費やされた CPU 時間の両方があり、合計で 2.1 秒です。riskセクションには Kudu が述語を評価できなかったという警告もあります。
<pre><code class="bash">SELECT * FROM transactions1g_kudu s07 left JOIN transactions1g_kudu s08 on s07.field_1 = s08.field_1
where s07.field_5 &lt;= ‘2000-01-31’ and s07.field_5 &gt;= ‘2000-01-01’;
[<img class="aligncenter size-full wp-image-5668" src="https://cdn.gethue.com/uploads/2019/03/Screen-Shot-2019-03-07-at-4.02.33-PM.png" alt="" width="460" height="600" />][19]
グラフを見ると、Kudu ノードは合計時間 727 ミリ秒のほとんどがIOになっていることが分かります。
### その他 {.p1}
ノードでは、実行時間が短く合計期間が長いクエリもあります。ここでは同じクエリを使用して、全てのノードの実行時間が10ミリ秒でしたが、クエリの実行は7.9秒でした。
[<img class="aligncenter wp-image-5675" src="https://cdn.gethue.com/uploads/2019/03/Screen-Shot-2019-03-07-at-10.56.07-AM.png" alt="" width="460" height="600" />][20]
グローバルのタイムラインを見ると、計画フェーズに3.8秒かかっており、ほとんどがメタデータのロードです。Impalaがテーブルに関するメタデータを持っていない場合、ユーザーの実行後に生じる可能性があります。
<pre><code class="bash">invalidate metadata;
Impalaはメタストアからメタデータを再フェッチする必要があります。さらに、4.1秒のうちの2番目に高価な項目は最初の行のフェッチであることが分かります。これはクライアント、この場合はHueが取得にかかった時間です。これらのイベントはどちらもユーザーが変更できるものではありませんが、どこで時間が費やされているかを確認するのが得策です。 where the time is spent.
<p class="p1">
いつものように、ご質問があれば <a href="http://groups.google.com/a/cloudera.org/group/hue-user">hue-userリスト</a> または <a href="https://twitter.com/gethue">@gethue</a>までコメントお待ちしています!
</p>