Hueを設定して、パブリッククラウドで、ユーザーがCSVファイルから新しいSQLテーブルを作成できるようにするのに苦労したことがある方は、これがはるかに簡単になったことを知って喜んでいただけると思います。
Hueのプロユーザーであれば、Hue のImporterをご存知でしょう。 ファイルからテーブルを作成することができます。 これまでは、ファイルはHDFSや、S3や ABFSなどのクラウドオブジェクトストレージ上にある必要がありました。 今では、コンピュータからファイルをブラウズして選択し、HueのさまざまなSQLの方言 でテーブルを作成できます。 Apache Hive, Apache Impala, Apache Phoenix, MySqlの方言に対応しています。
ゴール
- ソースに関係なく、Hue Importerを使用してファイルをアップロードする。
目的
- 誰もがHDFSやS3/ABFSにアクセスできるわけではありません。 ビジネスアナリストは、自分のコンピュータにあるデータセットを素早く分析し、データのクリーンアップやその他のデータエンジニアリングタスクを省略する必要があることがよくあります。
- この機能を使用すると、コンピュータからファイルをインポートして、数回のクリックでテーブルを作成することができます.
テーブルを作成する手順
ワークフロー
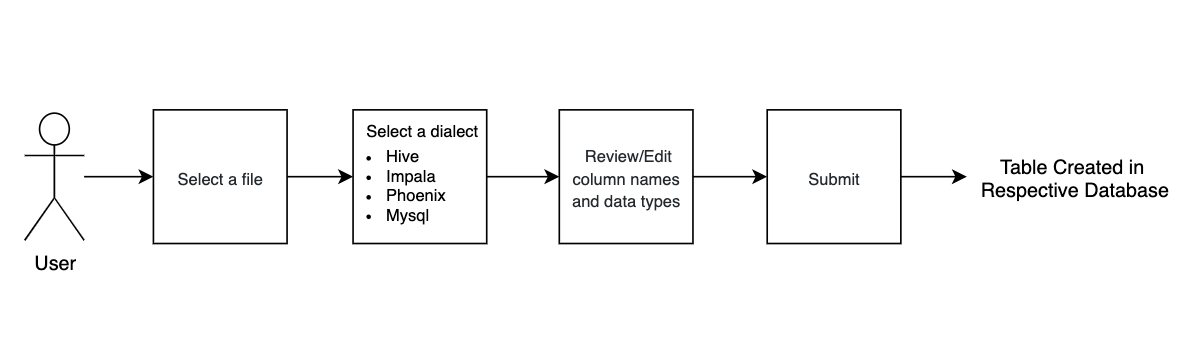
ファイルと API
- この機能を実装するために、3つのAPIを使用しています。
- Guess_format (ファイル形式を推測する)
- Guess_field_types (カラムの型を推測する)
- Importer_submit (テーブルを作成する)
- さまざまな SQL 方言がどのように実装されているのかに興味がある場合は、 sql.py ファイルをご覧ください。
注: 現在、Hueは数千行の小さなCSVファイルをサポートしています。
中間ステップ
- ステップ 1
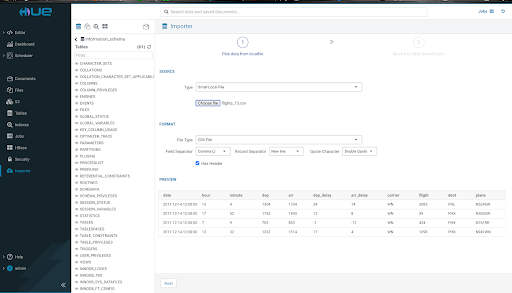
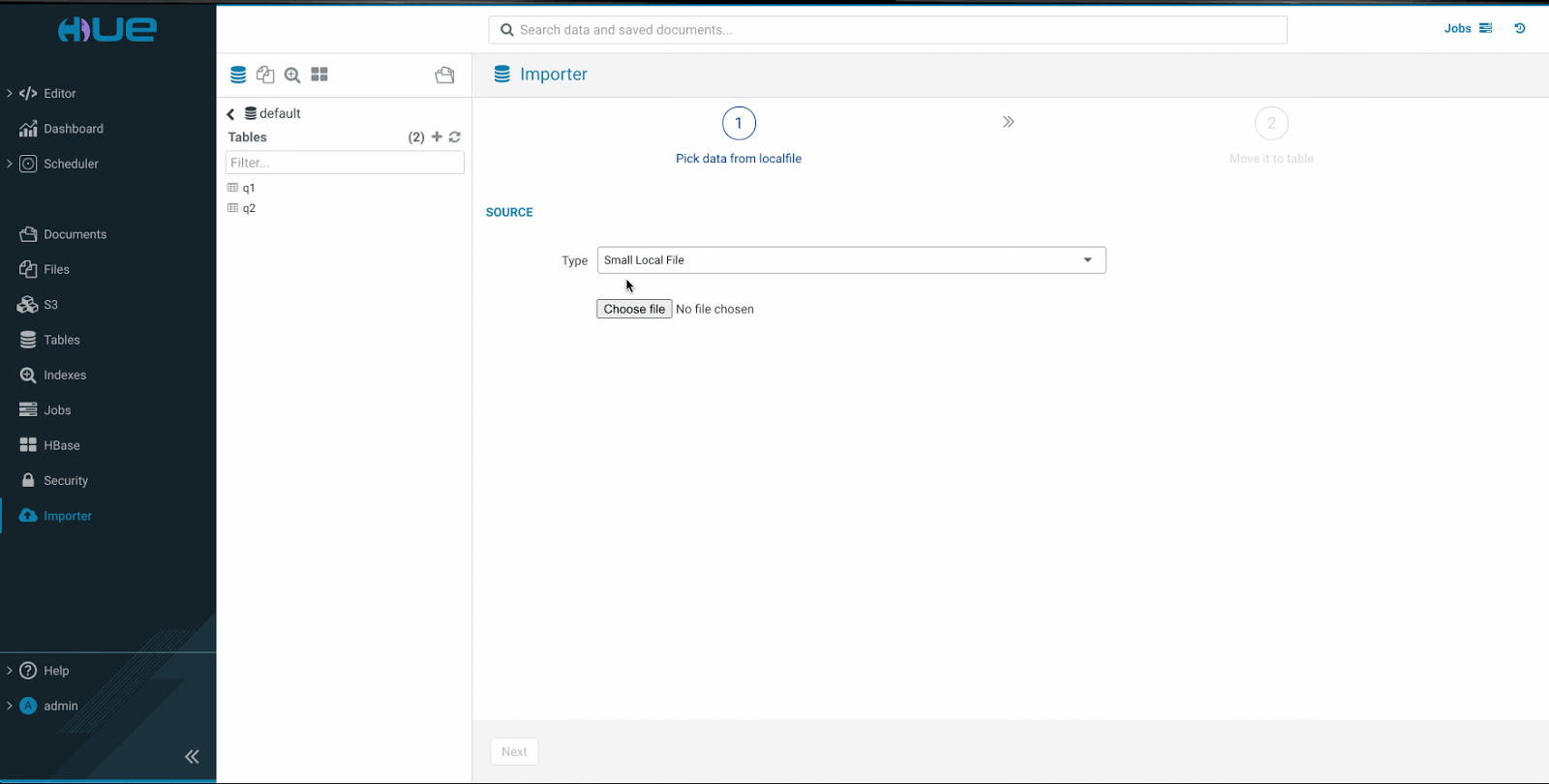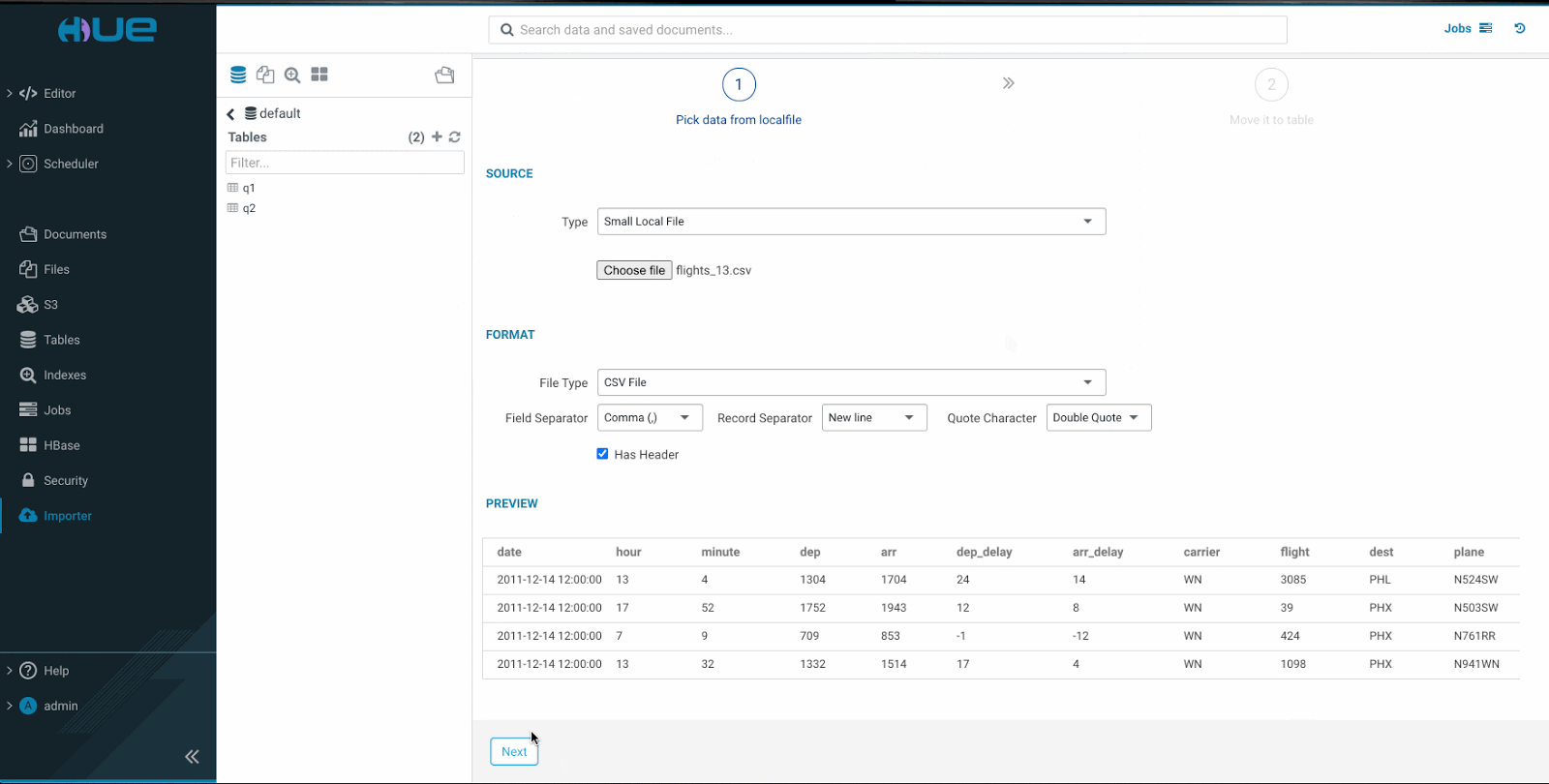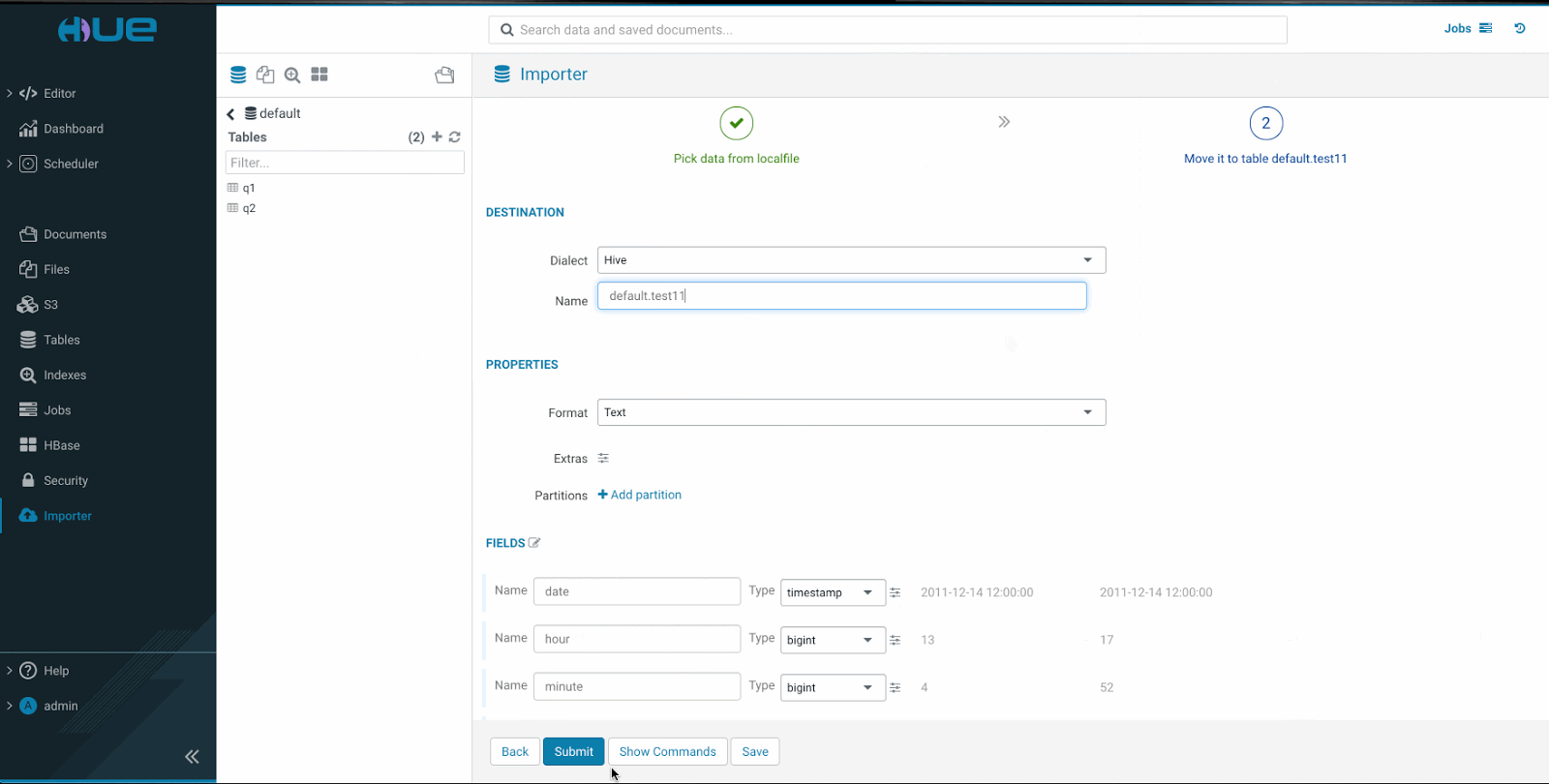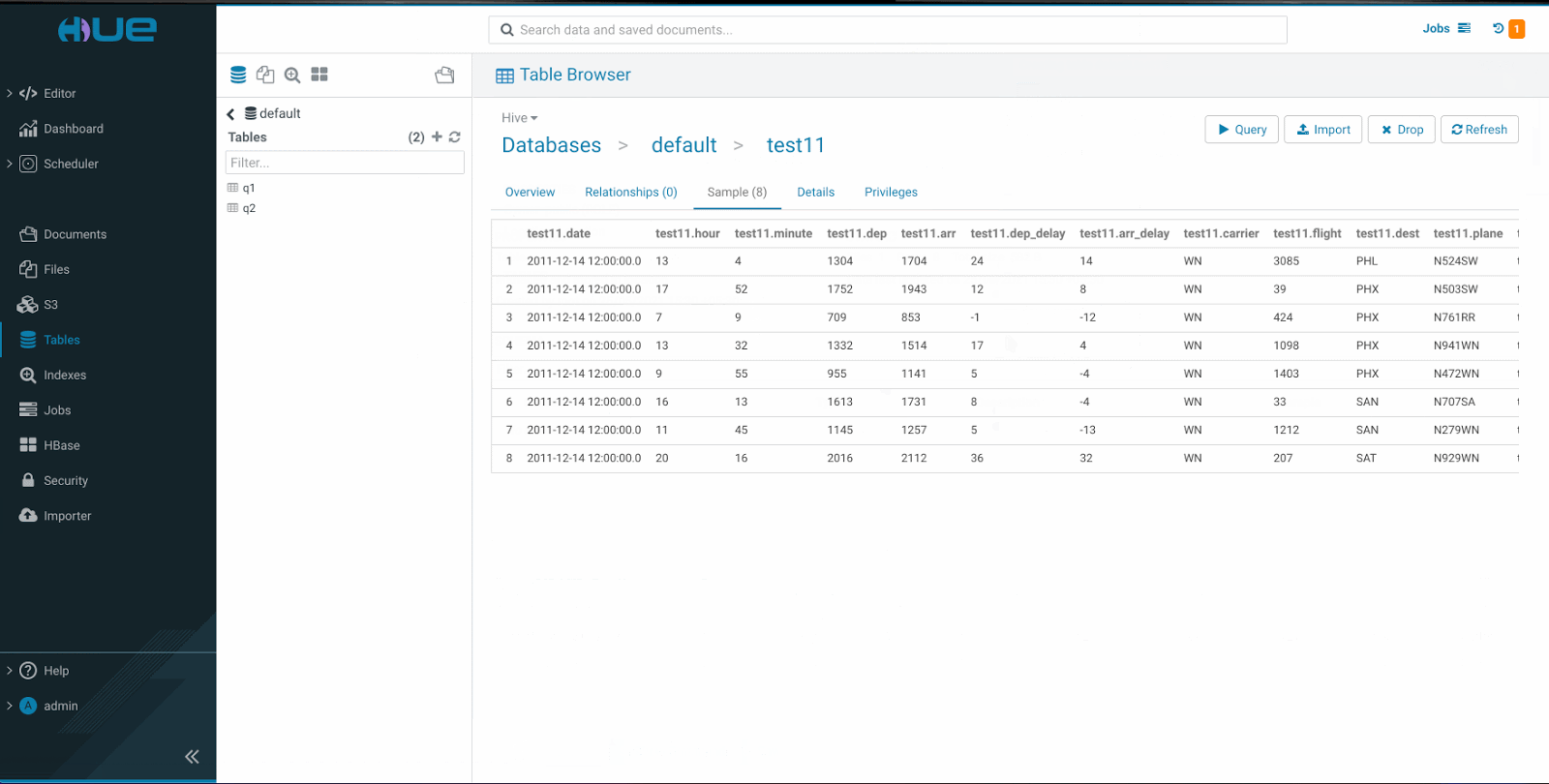
ファイルを選択すると、Hueはファイル形式を推測し、区切り文字を識別して、テーブルのプレビューを生成します。 - ステップ 2
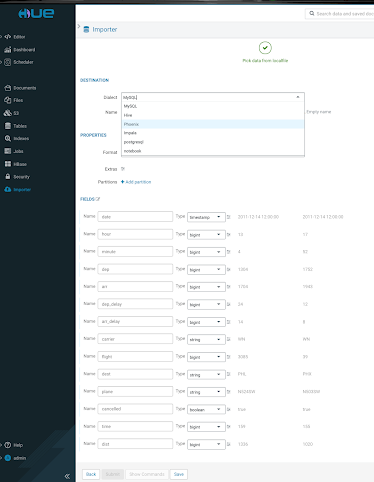
SQL の方言を選択すると、Hueは列のデータ型を自動検出します。 列名とそのデータ型は編集できます。
この機能は、最新の Hue または demo.gethue.com.
で試すことができます。 このプロジェクトでは、より多くのSQL方言をサポートするための貢献を喜んで歓迎いたします。
ご意見やご質問はありますか? ここやディスカッション まで気軽にコメントして、SQLクエリ のクイックスタートをしてください!
どうぞよろしくお願いします!
Ayush from the Hue Team