昨年、私たちは開発者がウェブインタフェースを介してSparkジョブを投入することができるSpark Igniterをリリースしました 。このアプローチが動作している間、UXが望まれたために多くを残しました。プログラムではインタフェースを実装する必要があり、事前にコンパイルされていなければならず、YARNのサポートが欠けていました。私たちは、REPLを使用するのと同様の、対話形式で反復型のプログラミングの経験を提供することにフォーカスし、PythonとScalaのサポートも追加したいと考えていました。 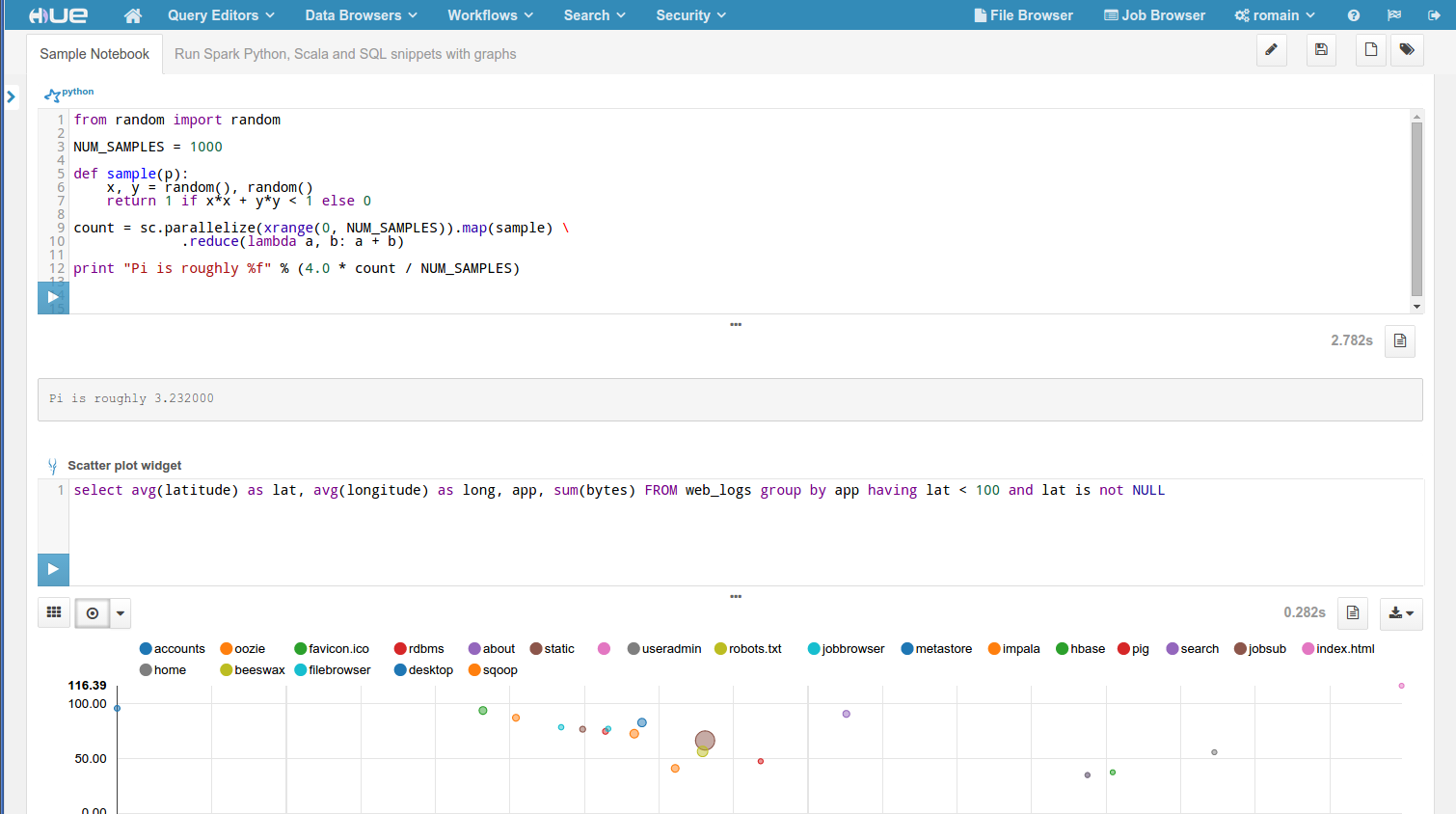 このため、私たちはこれらの不足している機能を提供することができるSpark REST Job Serverの開発を新たに始めました。その上に、私たちはPythonのNotebookのような雰囲気を提供するためのUIを刷新しました。
このため、私たちはこれらの不足している機能を提供することができるSpark REST Job Serverの開発を新たに始めました。その上に、私たちはPythonのNotebookのような雰囲気を提供するためのUIを刷新しました。
この新しいアプリケーションはかなり新しく、「ベータ版」として位置付けされていることにご注意ください。これは、それを試して貢献するのをお勧めすることを意味していますが、UXが多く進化していくため、その使用はまだ正式にはサポートされていません!
この投稿は、Webアプリケーションの一部を説明しています。私たちはSpark 1.3とHue マスターブランチを使用しています
これは、以下の新しい機能をベースにしています:
- Spark REST Job Server
- Notebook Web UI
サポート:
- Scala
- Python
- Java
- SQL
- YARN
Sparkアプリが「エディタ」メニューに表示されていない場合は、hue.iniから非ブラックリストする必要があります :
[desktop]
app_blacklist=
Hueと同じマシンでHueホームに移動します。
パッケージを使用してインストールしている場合:
cd /usr/lib/hue
Cloudera Managerを使用している場合:
cd /opt/cloudera/parcels/CDH/lib/
HUE_CONF_DIR=/var/run/cloudera-scm-agent/process/-hue-HUE_SERVER-id
echo $HUE_CONF_DIR
export HUE_CONF_DIR
そしてSpark Job Serverを起動します:
./build/env/bin/hue livy_serverhue.iniでこれらのプロパティを変更することで、セットアップをカスタマイズできます:
[spark]
# URL of the REST Spark Job Server.
server_url=http://localhost:8090/
# List of available types of snippets
languages='[{"name": "Scala", "type": "scala"},{"name": "Python", "type": "python"},{"name": "Impala SQL", "type": "impala"},{"name": "Hive SQL", "type": "hive"},{"name": "Text", "type": "text"}]'
# Uncomment to use the YARN mode
## livy_server_session_kind=yarn
さて、次は!
このベータ版は良い機能セットをもたらし、より多くが予定されています 。長期的には、すべてのクエリエディタ(例えばPig、DBquery、Pheonix…)がこの共通インターフェースを使用することを期待しています。その後、ビジュアルダッシュボードを作るために、個々のスニペットはドラッグ&ドロップできるようになり、ノートブックはDropboxやGoogle docsのように埋め込むことができるようになるかもしれません。
私たちは、新しいSpark REST Job Serverのフィードバックをいただくことにも関心があり、コミュニティがこれについてどのように考えているかを見ています (貢献を歓迎します;)