ビッグデータ愛好家の皆さん、こんにちは
Hueチームは、すべての貢献者のおかげでHue 3.10 がリリースできて嬉しく思います! ![]()
このリリースでフォーカスしていたのは、新しいSQLユーザーエクスペリエンスとパフォーマンスのコアを用意することでした。3.9の上に2000コミット以上が行われました!tarballのリリースを手に入れ展開して下さい!
どんな変更が行われたのか、詳細な説明は下記をご覧下さい。すべての変更についてはリリースノートやマニュアル を参照してください。
近日公開の詳細及びビデオチュートリアルシリーズも作業中です!
SQLエディタ

- 完全に刷新
- 任意の種類のSQLをサポート、他のSQLデータベースとの統合
- クエリ:マルチクエリ、検索と置換、ライブ履歴、折りたたみ、フォーマット、テーブルアシスト
- 結果:固定ヘッダ、列にスクロールし、グラフ作成、エクセル/ CSVでダウンロード
- 値のオートコンプリート、ネスとされたタイプ
SQLブラウザ
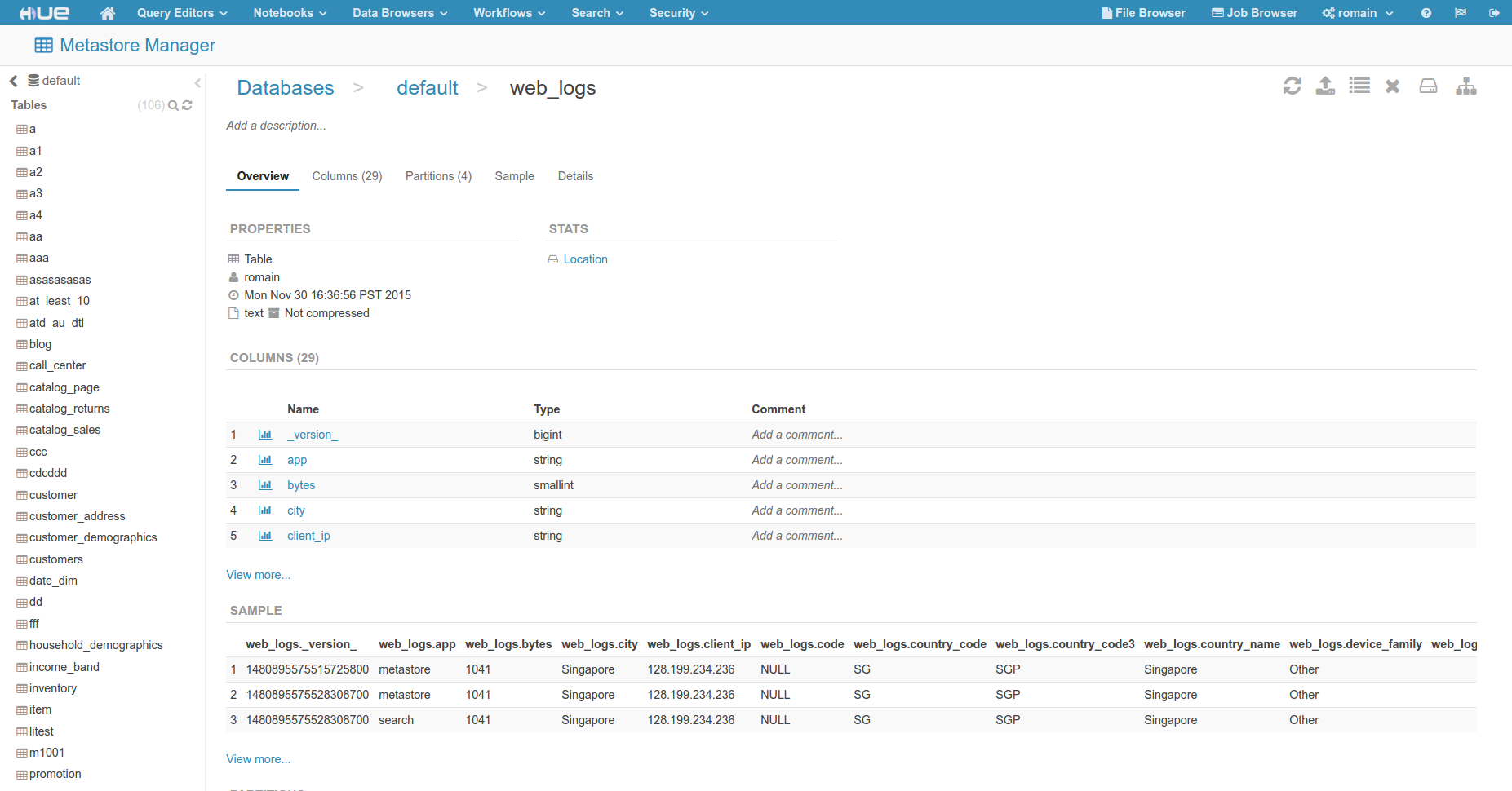
- 速度、統計の表示と使いやすさのためにUIを刷新
- 単一ページのアプリ
- 多くのデータベースとテーブル用に最適化
ホーム
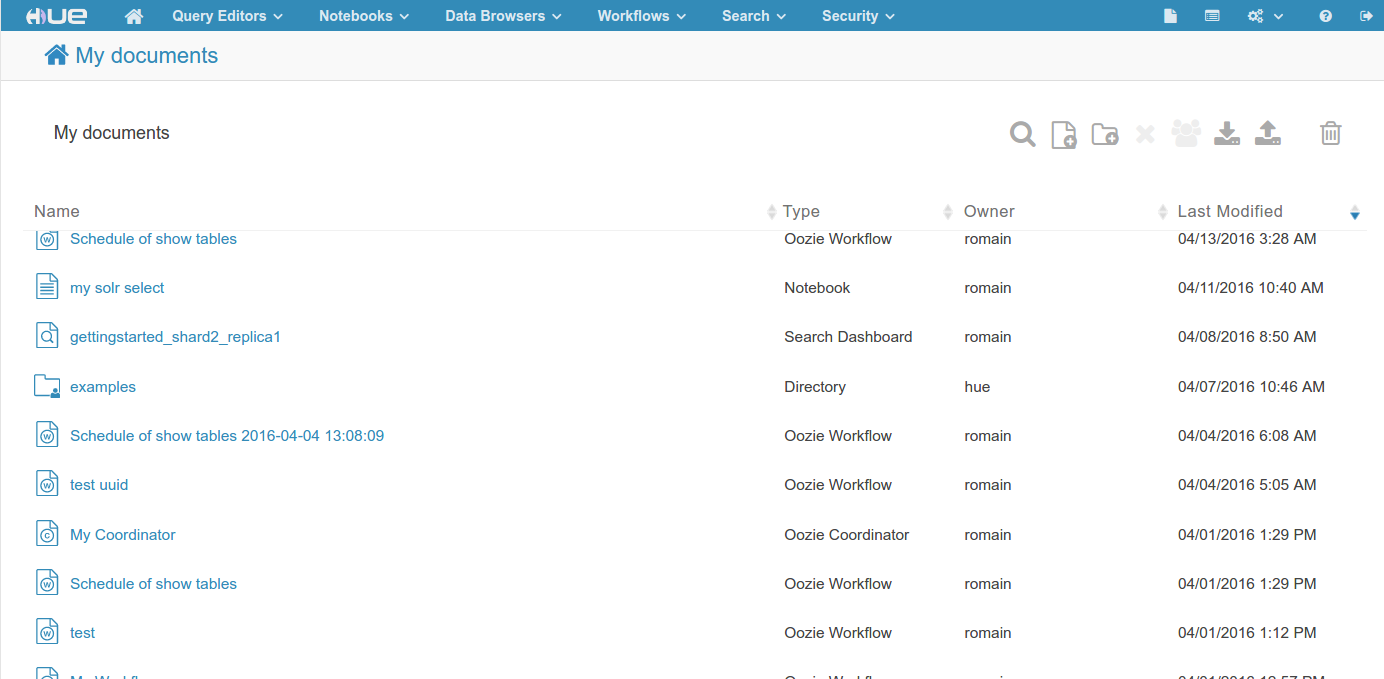
- フォルダとディレクトリ
- コラボレーションのための共有ドキュメント
- ドキュメントのエクスポートとインポート
Spark
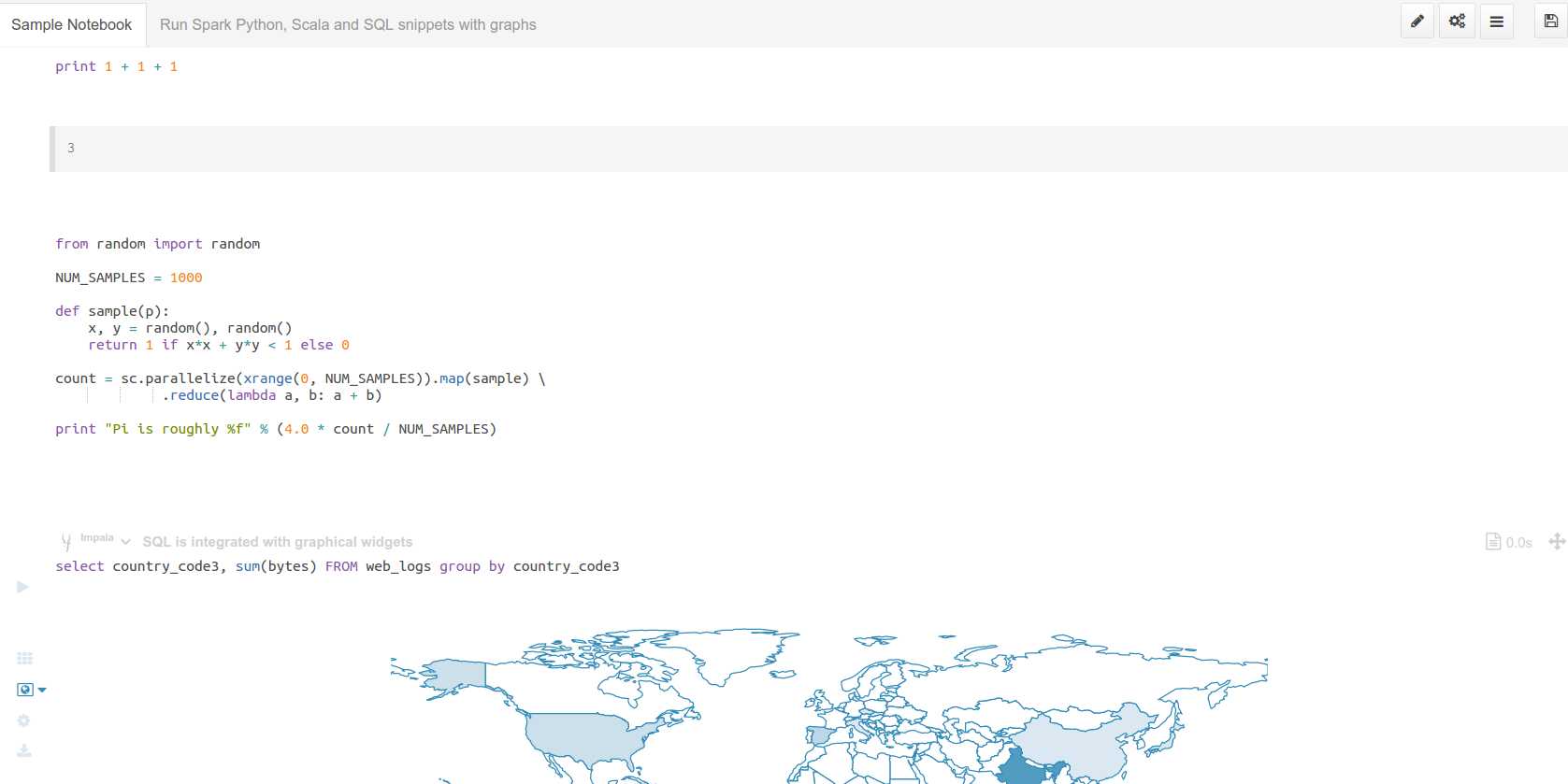
- その成功のため、Livyは専用リポジトリに移動されてされています: https://github.com/cloudera/livy
- バッチのJar、Pythonおよびストリーミングジョブを投入するためにLivy Spark RESTジョブサーバーAPIを使用する方法
- SparkのRDDとコンテキストを共有するためにLivy Spark RESTジョブサーバーAPIを使用する方法
- いくつかのインタラクティブなCurlとSparkを行うためにLivy Spark RESTジョブサーバーAPIを使用する方法
Search
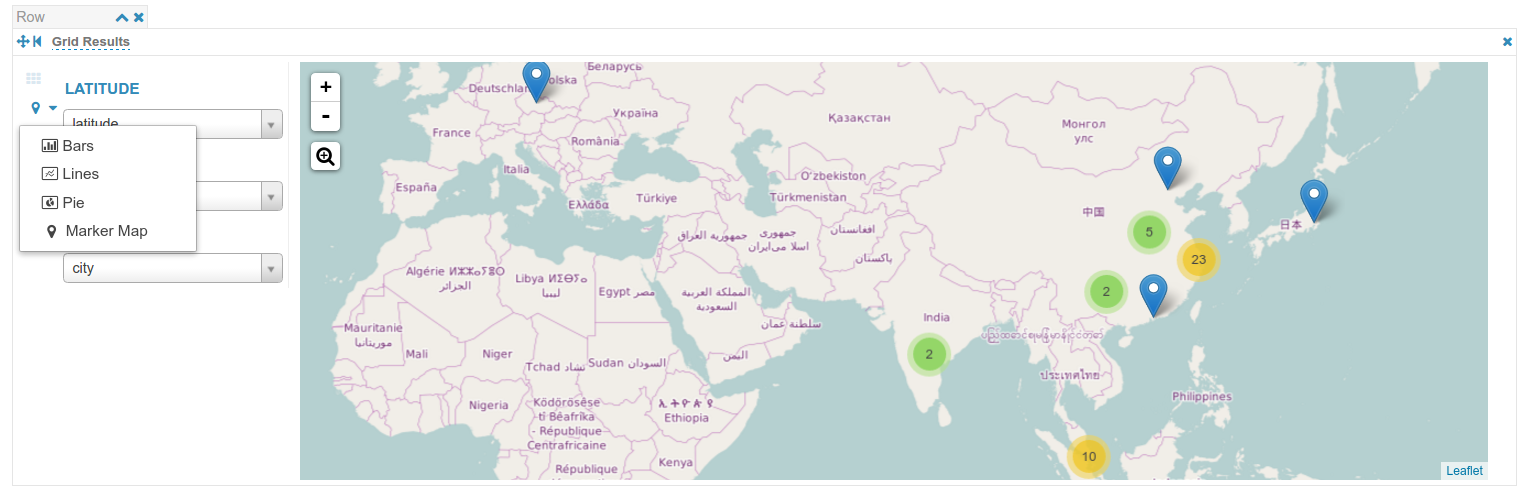
- HueはSolrのSuggestersをサポートし、データの検索が容易になります!Suggesterはクエリの自動補完可能なリストを提案することによりユーザーを支援します
- グリッドウィジェット内の結果はSQLエディタのようにプロットすることができます。これは検索クエリによって返された行をクリックして視覚化するのに最適です。
セキュリティ&スケーラビリティ
- パフォーマンスチューニング
- SolrのSentry権限版
- タイムアウトでは、
idle_session_timeout seconds後に非アクティブユーザーはログアウト - オプションで、
login_splash_htmlによりログインでのカスタムセキュリティスプラッシュ画面 - TLS証明書チェーン がHUEのサポート
- SAML
key_file_passwordでkey_fileのパスワードを導入xmlsec_binaryを変更することでxmlsec1バイナリをカスタマイズ- SAMLのユーザー名マッピングをカスタマイズ 。また、ログイン時にグループの同期をサポート
- Dockerにより1分でHue入門
- HiveまたはImpalaとなりすまし(Impersonation)でLDAPまたはPAMパススルー認証
- hue.iniの設定ではなくファイルのスクリプトにパスワードを保存
Oozie
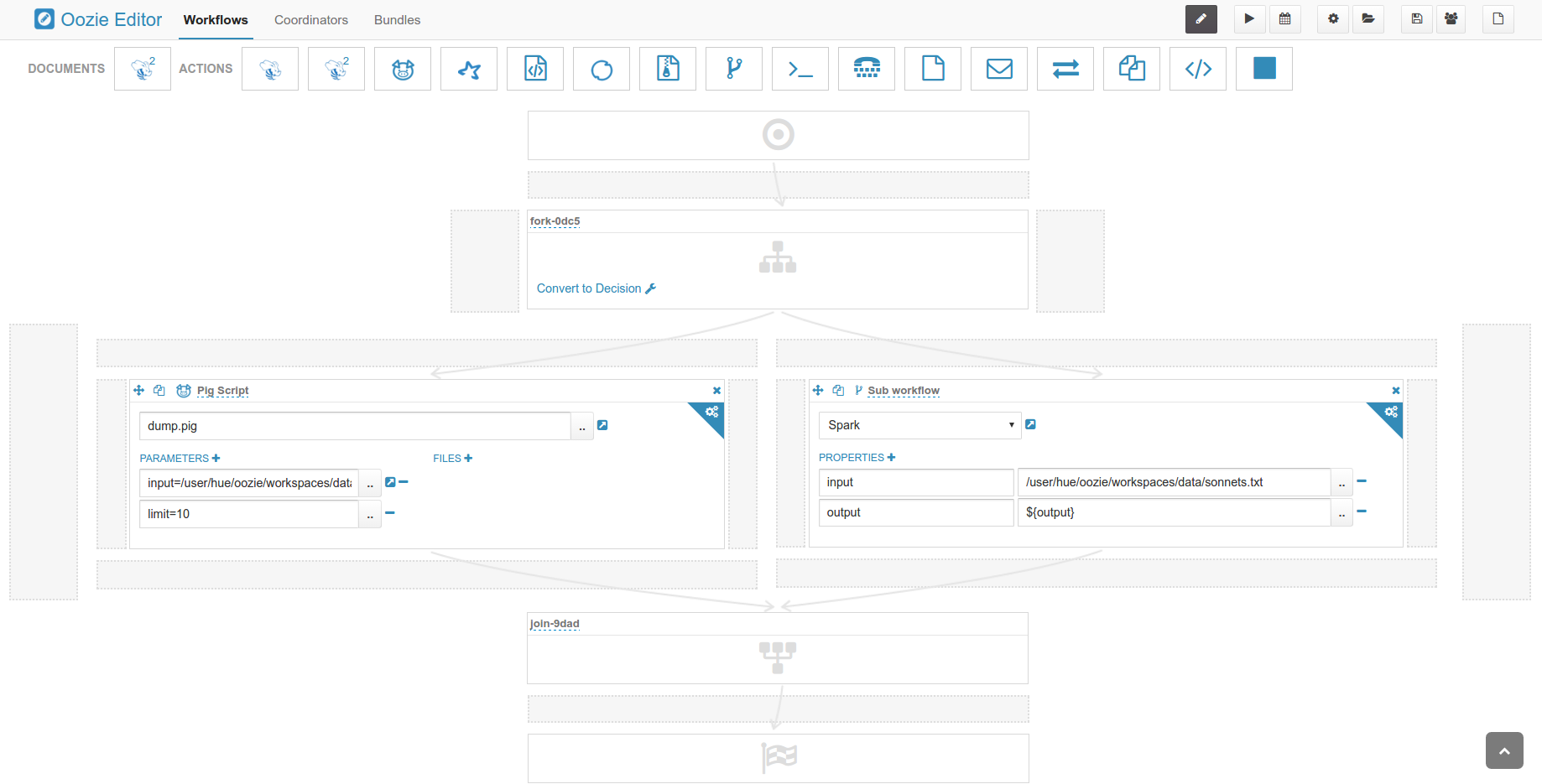
- 外部ワークフローグラフ:この機能はファイルブラウザのフォームから投入されたワークフローだけではなく、CLIから投入されたワークフローのグラフが見ることができる
- Dryrun Oozieジョブ:Dryrun オプションは指定されたプロパティを持つワークフロー/コーディネーター/バンドルジョブをの実行をテストし、ジョブを作成しない
- タイムゾーンの改善:現在ダッシュボード上のすべての時刻はブラウザのタイムゾーンのデフォルトで、コーディネーター/バンドルの投入では、もうUTC時間は必要ない
- 失敗時に自動的にメールで送信:現在各Kill nodeにはオプションのEmailアクションが組み込まれているKill nodeが呼び出される場合のカスタムメッセージを挿入するために Kill nodeを編集
( 詳細を読む)
HDFS
![]()
ディスク容量の消費、クォータとディレクトリおよびファイルの数にアクセスするにはファイルまたはディレクトリを右クリック
チュートリアル
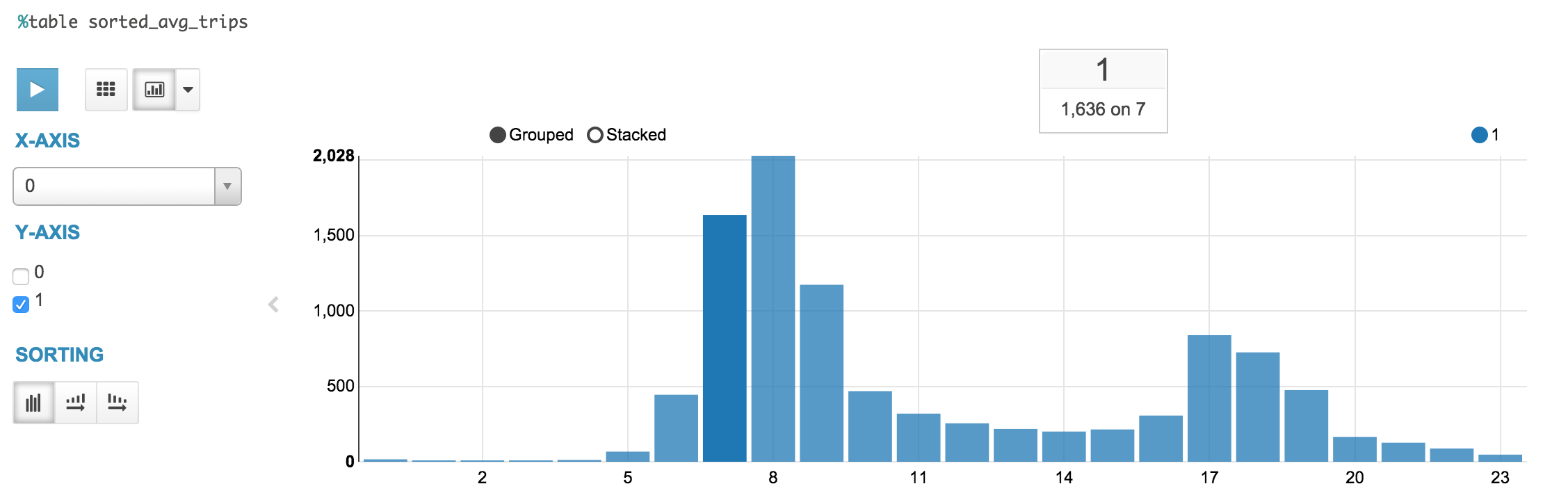
- Hadoopのノートブックとスパーク&SQLを使用したベイエリアのバイクシェア分析パート1
- Hadoopのノートブックとスパーク&SQLを使用したベイエリアのバイクシェア分析パート2
- Oozieでシェルアクションを使用する
- OozieでSparkアクションを使用する
カンファレンス

Big Data Budapest Meetup, Big Data Amsterdam, Hadoop Summit San Jose および Big Data LAで講演ができたのは嬉しいことでした。
- Spark Summit Europe:サービスとしてインタラクティブなSparkのためのREST Job Serverの構築
- Solr SF Meetup:あなたのビッグデータの対話的な検索と視覚化
- Big Data Scala by the Bay:あなたのブラウザでインタラクティブなSpark
チームの避暑

- ベトナム、賑やかなホーチミン市、banh mi、pho bo、暖かい海水、豪華な天候
- スペインのビーチとアムステルダム
- オランダのブルメンダールでチューリップやビールは偉大だった
さて次は!
次の版(Hue 3.11、第3四半期の終わりを想定)では、SQLの改善、ジョブの監視とクラウドの統合に焦点を当てる予定です。
Hue 4の設計も「ビッグデータのためのExcel」同等になることを目標に継続しています。新鮮な新しい外観、すべてのアプリケーションの統合、データを摂取するためのウィザード…あなたは高速なビッグデータのクエリとプロトタイピングのための単一のUIで、完全なプラットフォーム(SQL、検索、Spark、摂取(インジェスト))が使用できるようになります!
その先へ!
すべてのプロジェクトの貢献者の皆様、フィードバックの送信やhue-userメーリングリストや@gethueにご参加いただいている皆様、いつもありがとうございます!