Livyは任意の場所からSparkと対話的に使用するためのオープンソースのRESTインターフェースです。LivyはローカルまたはYARNで実行される、Spark Contextのコードやプログラムのスニペットの実行をサポートしています。
私たちは、以前に対話的なシェルAPI (別名sparkシェル)の使用方法と、 リモート共有RDDの作成方法について説明しました 。このフォローアップでは、私たちはYARNでバッチジョブ(別名spark-submit)を実行する方法を見ていきます。これらのジョブはJavaやScalaをコンパイルしてJarにしたもの、あるいは単にPythonのファイルです。Livyを使用することのいくつかの利点は、ジョブをリモートから投入でき、特別なインタフェースを実装したり再コンパイルする必要がないことです。
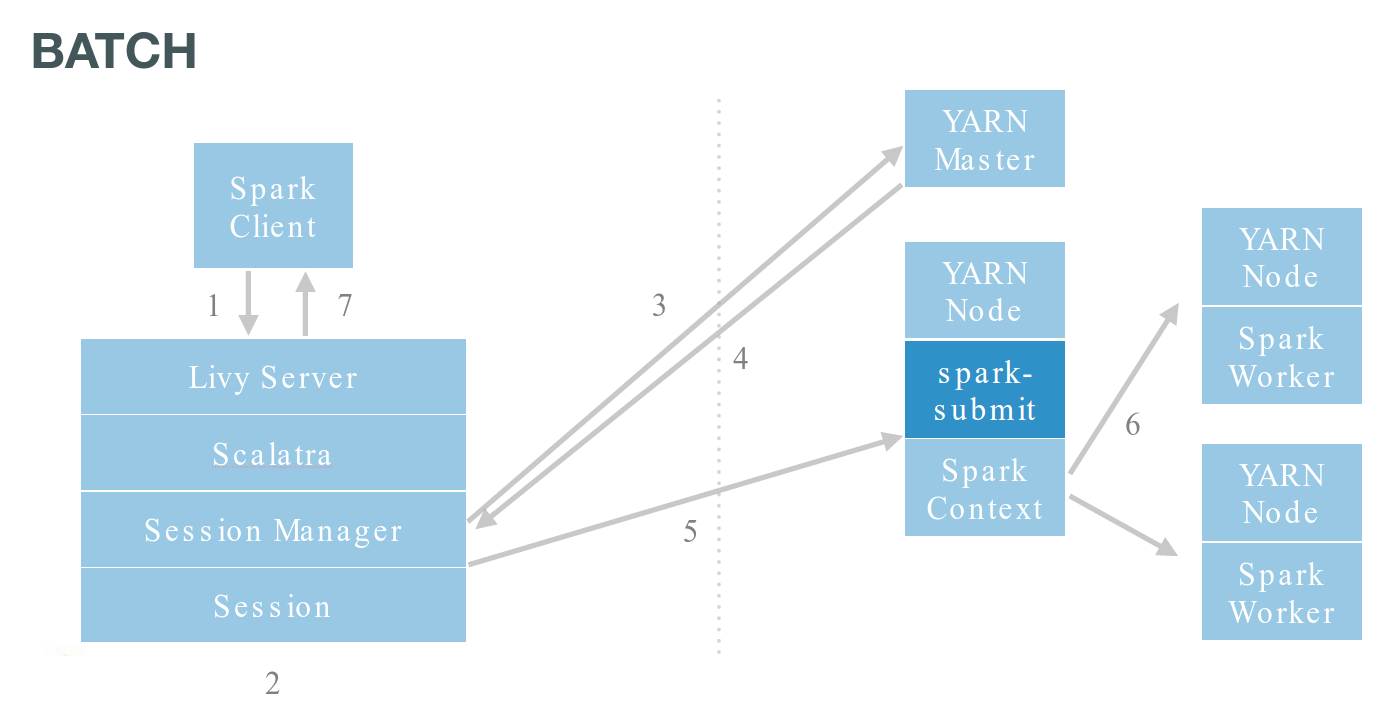
Livyはspark-submitをラップし、リモートで実行します
RESTサーバを起動する
これは以前の記事のセクションに記載されています 。
ここではYARN モードを使用しているので、すべてのパスはHDFS上に存在する必要があります。ローカルの開発モードでは、あなたのマシン上のローカルパスを使用するだけです。
Jarを投入する
Livyはjarとpyファイルと動作するspark-submitのラッパーを提供しています。APIは対話的なものとは少し異なっています。アクティブな実行中のジョブを一覧表示することから始めてみましょう:
curl localhost:8998/sessions | python -m json.tool % Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 34 0 34 0 0 2314 0 --:--:-- --:--:-- --:--:-- 2428
{
"from": 0,
"sessions": [],
"total": 0
}
その後、SparkのサンプルのJarである/usr/lib/spark/lib/spark-examples.jarをHDFSにアッップロードして示すようにします。LivyをYARNモードではなくローカルモードで使用している場合は、単にローカルのパス/usr/lib/spark/lib/spark-examples.jar を維持するだけです。
curl -X POST --data '{"file": "/user/romain/spark-examples.jar", "className": "org.apache.spark.examples.SparkPi"}' -H "Content-Type: application/json" localhost:8998/batches
{"id":0,"state":"running","log":[]}
We get the submission id, in our case 0, and can check its progress. It should actually already be done:
curl localhost:8998/batches/0 | python -m json.tool
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 902 0 902 0 0 91120 0 --:--:-- --:--:-- --:--:-- 97k
{
"id": 0,
"log": [
"15/10/20 16:32:21 INFO ui.SparkUI: Stopped Spark web UI at http://192.168.1.30:4040",
"15/10/20 16:32:21 INFO scheduler.DAGScheduler: Stopping DAGScheduler",
"15/10/20 16:32:21 INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!",
"15/10/20 16:32:21 INFO storage.MemoryStore: MemoryStore cleared",
"15/10/20 16:32:21 INFO storage.BlockManager: BlockManager stopped",
"15/10/20 16:32:21 INFO storage.BlockManagerMaster: BlockManagerMaster stopped",
"15/10/20 16:32:21 INFO scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!",
"15/10/20 16:32:21 INFO spark.SparkContext: Successfully stopped SparkContext",
"15/10/20 16:32:21 INFO util.ShutdownHookManager: Shutdown hook called",
"15/10/20 16:32:21 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-6e362908-465a-4c67-baa1-3dcf2d91449c"
],
"state": "success"
}
出力ログを見ることができます:
curl localhost:8998/batches/0/log | python -m json.tool
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 5378 0 5378 0 0 570k 0 --:--:-- --:--:-- --:--:-- 583k
{
"from": 0,
"id": 3,
"log": [
"SLF4J: Class path contains multiple SLF4J bindings.",
"SLF4J: Found binding in [jar:file:/usr/lib/zookeeper/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]",
"SLF4J: Found binding in [jar:file:/usr/lib/flume-ng/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]",
"SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.",
"SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]",
"15/10/21 01:37:27 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable",
"15/10/21 01:37:27 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032",
"15/10/21 01:37:27 INFO yarn.Client: Requesting a new application from cluster with 1 NodeManagers",
"15/10/21 01:37:27 INFO yarn.Client: Verifying our application has not requested more than the maximum memory capability of the cluster (8192 MB per container)",
"15/10/21 01:37:27 INFO yarn.Client: Will allocate AM container, with 1408 MB memory including 384 MB overhead",
"15/10/21 01:37:27 INFO yarn.Client: Setting up container launch context for our AM",
"15/10/21 01:37:27 INFO yarn.Client: Setting up the launch environment for our AM container",
"15/10/21 01:37:27 INFO yarn.Client: Preparing resources for our AM container",
....
....
"15/10/21 01:37:40 INFO yarn.Client: Application report for application_1444917524249_0004 (state: RUNNING)",
"15/10/21 01:37:41 INFO yarn.Client: Application report for application_1444917524249_0004 (state: RUNNING)",
"15/10/21 01:37:42 INFO yarn.Client: Application report for application_1444917524249_0004 (state: FINISHED)",
"15/10/21 01:37:42 INFO yarn.Client: ",
"\t client token: N/A",
"\t diagnostics: N/A",
"\t ApplicationMaster host: 192.168.1.30",
"\t ApplicationMaster RPC port: 0",
"\t queue: root.romain",
"\t start time: 1445416649481",
"\t final status: SUCCEEDED",
"\t tracking URL: http://unreal:8088/proxy/application_1444917524249_0004/A",
"\t user: romain",
"15/10/21 01:37:42 INFO util.ShutdownHookManager: Shutdown hook called",
"15/10/21 01:37:42 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-26cdc4d9-071e-4420-a2f9-308a61af592c"
],
"total": 67
}
例えば、結果をより正確でより長く実行するように、100回の繰り返しを行うためにコマンドに引数を追加することができます:
curl -X POST --data '{"file": "/usr/lib/spark/lib/spark-examples.jar", "className": "org.apache.spark.examples.SparkPi", "args": ["100"]}' -H "Content-Type: application/json" localhost:8998/batches
{"id":1,"state":"running","log":[]}
実行中のジョブを停止したい場合、以下のように発行します:
curl -X DELETE localhost:8998/batches/1
{"msg":"deleted"}
別の機会にそれを実行すると、ジョブはLivyから削除されているので何も表示されません:
curl -X DELETE localhost:8998/batches/1
session not found
Pythonのジョブを投入する
Pythonのジョブの投入はJarのジョブとほぼ同じです。スパークのサンプルを解凍してpi.pyをHDFSにアップロードします:
~/tmp$ tar -zxvf /usr/lib/spark/examples/lib/python.tar.gz
./
./sql.py
./kmeans.py
./cassandra_outputformat.py
./mllib/
./mllib/correlations.py
./mllib/kmeans.py
....
....
./streaming/flume_wordcount.py
./streaming/recoverable_network_wordcount.py
./streaming/hdfs_wordcount.py
./streaming/kafka_wordcount.py
./streaming/stateful_network_wordcount.py
./streaming/sql_network_wordcount.py
./streaming/mqtt_wordcount.py
./streaming/network_wordcount.py
./streaming/direct_kafka_wordcount.py
./wordcount.py
./pi.py
./hbase_inputformat.py
その後、ジョブを開始します。:
curl -X POST --data '{"file": "/user/romain/pi.py"}' -H "Content-Type: application/json" localhost:8998/batches
{"id":2,"state":"starting","log":[]}いつものように、単純なGETでステータスを確認することができます:
curl localhost:8998/batches/2 | python -m json.tool
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 616 0 616 0 0 77552 0 --:--:-- --:--:-- --:--:-- 88000
{
"id": 2,
"log": [
"\t ApplicationMaster host: 192.168.1.30",
"\t ApplicationMaster RPC port: 0",
"\t queue: root.romain",
"\t start time: 1445417899564",
"\t final status: UNDEFINED",
"\t tracking URL: http://unreal:8088/proxy/application_1444917524249_0006/",
"\t user: romain",
"15/10/21 01:58:26 INFO yarn.Client: Application report for application_1444917524249_0006 (state: RUNNING)",
"15/10/21 01:58:27 INFO yarn.Client: Application report for application_1444917524249_0006 (state: RUNNING)",
"15/10/21 01:58:28 INFO yarn.Client: Application report for application_1444917524249_0006 (state: RUNNING)"
],
"state": "running"
}
そして、/log接尾辞を追加して出力します!
curl localhost:8998/batches/2/log | python -m json.toolストリーミングジョブを投入する
多くの場合、ストリーミングは投入したバッチジョブで構成されています。これはライブツイートを収集し、動的検索ダッシュボードにインデックスするSolr Sparkストリーミングジョブを投入する方法です。
Jarファイルをコンパイルした後にHDFSにアップロードし、そしてtwitter4j.propertiesもアップロードします。
curl -X POST --data '{"file": "/user/romain/spark-solr-1.0-SNAPSHOT.jar", "className": "com.lucidworks.spark.SparkApp", "args": ["twitter-to-solr", "-zkHost", "localhost:9983", "-collection", "tweets"], "files": ["/user/romain/twitter4j.properties"]}' -H "Content-Type: application/json" localhost:8998/batches
{"id":3,"state":"starting","log":[]}
ステータスを確認し、それが正しく実行されていることをチェックします:
curl localhost:8998/batches/3 | python -m json.tool
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 842 0 842 0 0 82947 0 --:--:-- --:--:-- --:--:-- 84200
{
"id": 3,
"log": [
"\t start time: 1445420201439",
"\t final status: UNDEFINED",
"\t tracking URL: http://unreal:8088/proxy/application_1444917524249_0009/",
"\t user: romain",
"15/10/21 02:36:47 INFO yarn.Client: Application report for application_1444917524249_0009 (state: RUNNING)",
"15/10/21 02:36:48 INFO yarn.Client: Application report for application_1444917524249_0009 (state: RUNNING)",
"15/10/21 02:36:49 INFO yarn.Client: Application report for application_1444917524249_0009 (state: RUNNING)",
"15/10/21 02:36:50 INFO yarn.Client: Application report for application_1444917524249_0009 (state: RUNNING)",
"15/10/21 02:36:51 INFO yarn.Client: Application report for application_1444917524249_0009 (state: RUNNING)",
"15/10/21 02:36:52 INFO yarn.Client: Application report for application_1444917524249_0009 (state: RUNNING)"
],
"state": "running"
}
ダッシュボードを開いてブログの記事のように設定した場合、ツイートが来るのを見ることができます:

最後に、以下のようにしてジョブを停止できます:
curl -X DELETE localhost:8998/batches/3
追加のspark-submitプロパティをどのように指定するかのために、Batch API documentationを参照することができます。例えば、カスタムの名前やキューを追加するには:
curl -X POST --data '{"file": "/usr/lib/spark/lib/spark-examples.jar", "className": "org.apache.spark.examples.SparkPi", "queue": "my_queue", "name": "Livy Pi Example"}' -H "Content-Type: application/json" localhost:8998/batches次回はマジックキーワードと、IPythonとのより良い統合方法について調査します!
Livy Spark REST APIについてさらに学習したい方はユーザーリストやアムステルダムのSpark Summitで気軽に直接質問を送ってください!