HueはブラウザからScalaとJavaのジョブを直接サブミットできるSpark Applicationを同梱しています。
Sparkとやり取りするために、オープンソースのSpark Job Serverを使用します。 (例: 一覧、Sparkジョブの投入、結果の取得、コンテキストの作成…)
これは、サービスとしてSpark Job Serverを実行する方法の詳細です。これは、以前記事で説明したデプロイモードに対して実働環境により適しています。私たちはCDH5.0とSpark 0.9を使用しています。
サーバーのパッケージとデプロイ
ほとんどの使用方法はgithubにあります。
レポジトリをチェックアウトし、プロジェクトをビルドすることによって開始します。(注:Ubuntuを使ってディスクを暗号化している場合、/tmpの構築をする必要があります)。続いてSpark Job Serverのルートディレクトリから:
mkdir bin/config
cp config/local.sh.template bin/config/settings.sh
そして、settings.shのこれら2つの変数を:
LOG_DIR=/var/log/job-server
SPARK_HOME=/usr/lib/spark (or SPARK_HOME=/opt/cloudera/parcels/CDH/lib/spark)
それから全てをパッケージします:
bin/server_deploy.sh settings.sh
[info] - should return error message if classPath does not match
[info] - should error out if loading garbage jar
[info] - should error out if job validation fails
...
[info] Packaging /tmp/spark-jobserver/job-server/target/spark-job-server.jar ...
[info] Done packaging.
[success] Total time: 149 s, completed Jun 2, 2014 5:15:14 PM
/tmp/job-server /tmp/spark-jobserver
log4j-server.properties
server_start.sh
spark-job-server.jar
/tmp/spark-jobserver
Created distribution at /tmp/job-server/job-server.tar.gz
主要なtarbal、tarball /tmp/job-server/job-server.tar.gzを持っており、サーバーにコピーする準備ができています。
注:
server_deploy.shで自動的にファイルをコピーすることもできます。
Spark Job Serverを開始する
それからjob-server.tar.gzを展開し、サーバーのapplication.confをコピーします。’master’が正しいSpark MasterのURLを示していることを確認して下さい。
scp /tmp/spark-jobserver/./job-server/src/main/resources/application.conf [email protected]:
masterを示すようにapplication.confを編集します:
# Settings for safe local mode development
spark {
master = "spark://spark-host:7077"
…
}
これがjobserverフォルダーの内容です:
ls -l
total 25208
-rw-rw-r-- 1 ubuntu ubuntu 2015 Jun 9 23:05 demo.conf
-rw-rw-r-- 1 ubuntu ubuntu 2563 Jun 11 16:32 gc.out
-rw-rw-r-- 1 ubuntu ubuntu 588 Jun 9 23:05 log4j-server.properties
-rwxrwxr-x 1 ubuntu ubuntu 2020 Jun 9 23:05 server_start.sh
-rw-rw-r-- 1 ubuntu ubuntu 366 Jun 9 23:13 settings.sh
-rw-rw-r-- 1 ubuntu ubuntu 13673788 Jun 9 23:05 spark-job-server.jar
注:
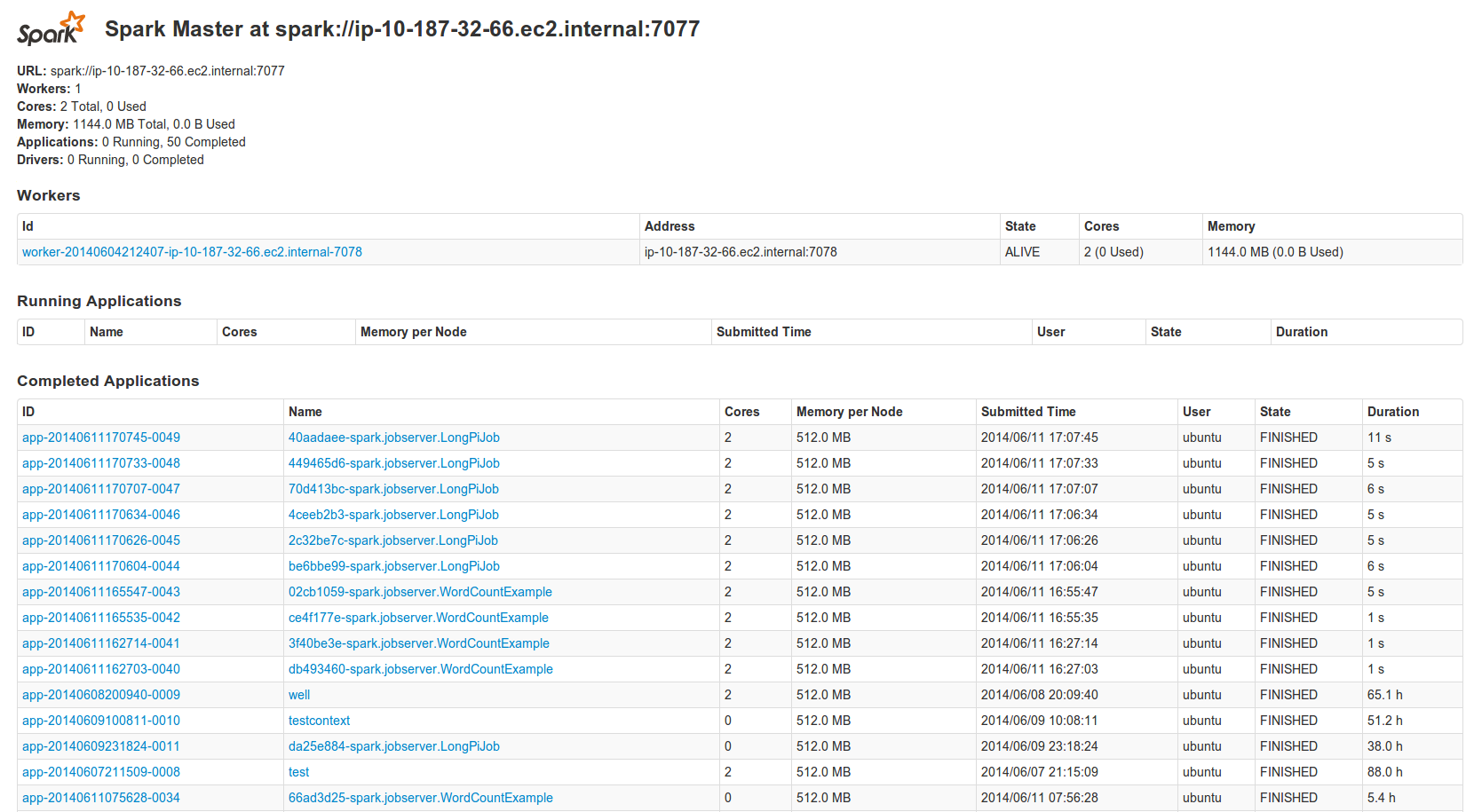
Spark Master Web UIを調査してsparkのURLを得ることもできます。
少なくともひとつのSpark workerがあることも確認します: "Workers: 1"
従来は、Sparkをlocalhostにバインドしようとした時にいくつかの問題がありました (例 spark workerが開始しない)。私たちはspark-env.shにハードコードすることで修正しています:
sudo vim /etc/spark/conf/spark-env.sh
export STANDALONE_SPARK_MASTER_HOST=spark-host
ここでサーバーを開始して、プロセスをバックグラウンドで実行します:
./server_start.shgrepして動作しているかを確認することができます:
ps -ef | grep 9999
ubuntu 28755 1 2 01:41 pts/0 00:00:11 java -cp /home/ubuntu/spark-server:/home/ubuntu/spark-server/spark-job-server.jar::/opt/cloudera/parcels/CDH-5.0.0-1.cdh5.0.0.p0.47/lib/spark/conf:/opt/cloudera/parcels/CDH-5.0.0-1.cdh5.0.0.p0.47/lib/spark/assembly/lib/*:/opt/cloudera/parcels/CDH-5.0.0-1.cdh5.0.0.p0.47/lib/spark/examples/lib/*:/etc/hadoop/conf:/opt/cloudera/parcels/CDH-5.0.0-1.cdh5.0.0.p0.47/lib/hadoop/*:/opt/cloudera/parcels/CDH-5.0.0-1.cdh5.0.0.p0.47/lib/hadoop/../hadoop-hdfs/*:/opt/cloudera/parcels/CDH-5.0.0-1.cdh5.0.0.p0.47/lib/hadoop/../hadoop-yarn/*:/opt/cloudera/parcels/CDH-5.0.0-1.cdh5.0.0.p0.47/lib/hadoop/../hadoop-mapreduce/*:/opt/cloudera/parcels/CDH-5.0.0-1.cdh5.0.0.p0.47/lib/spark/lib/scala-library.jar:/opt/cloudera/parcels/CDH-5.0.0-1.cdh5.0.0.p0.47/lib/spark/lib/scala-compiler.jar:/opt/cloudera/parcels/CDH-5.0.0-1.cdh5.0.0.p0.47/lib/spark/lib/jline.jar -XX:+UseConcMarkSweepGC -verbose:gc -XX:+PrintGCTimeStamps -Xloggc:/home/ubuntu/spark-server/gc.out -XX:MaxPermSize=512m -XX:+CMSClassUnloadingEnabled -Xmx5g -XX:MaxDirectMemorySize=512M -XX:+HeapDumpOnOutOfMemoryError -Djava.net.preferIPv4Stack=true -Dcom.sun.management.jmxremote.port=9999 -Dcom.sun.manage
これだけです!
Piのサンプルを実行する!
Spark Job Serverは、一つのコマンドドでビルドできるいくつかの例を備えています。Pi ジョブを実行しましょう。
http://hue:8888/sparkでSpark Appをオープンし、applicationタブに移動してjob-server-tests-0.3.x.jarをアップロードします。
ここでエディタにて、この実行するクラスspark.jobserver.LongPiJobを指定し、実行します!
Spark MasterのUIでもSparkアプリケーションが実行していることがわかるでしょう。長時間実行しているアプリケーションを取得したい場合、コンテキストを作成し、その後このコンテキストをエディタでアプリケーションに割り当てます。
まとめ
これはThis is how we setup the Spark Server on demo.gethue.com/sparkでSpark Serverをどのようにセットアップするかを示しています。いつものように、コメントはhue-userメーリングリストや@gethueまでお気軽に!
Happy Sparking!
PS: Hue or Job Server talks at the upcoming Spark SummitでのhueまたはJob Serverのセッションでお会いできることを楽しみにしています!