リアルタイムでのデータクエリは現代の標準になりつつあります。今すぐに決定を下す必要があるときに、翌日や一週間先まで待ちたい人はいないでしょう。
データのストリームは ksqlDB を介してクエリできる Apache Kafka のトピックから来ています。
コンポーネント
シンプルにするために、すべてのトピックは “one-click” Docker Compose プロジェクトにまとめられており、これらが含まれています:
- ksqlDB - ksqlDB quickstart から
- Hue Editor - ksqlDB エディタを使用するように設定されています
一行でのセットアップ
設定をフェッチして全てを開始するためのものです:
mkdir stream-sql-demo
cd stream-sql-demo
wget https://raw.githubusercontent.com/romainr/query-demo/master/stream-sql-demo/docker-compose.yml
docker-compose up -d
>
Creating network "stream-sql-demo_default" with the default driver
Creating hue-database ... done
Creating stream-sql-demo_jobmanager_1 ... done
Creating stream-sql-demo_mysql_1 ... done
Creating ksqldb-server ... done
Creating stream-sql-demo_zookeeper_1 ... done
Creating flink-sql-api ... done
Creating stream-sql-demo_taskmanager_1 ... done
Creating hue ... done
Creating ksqldb-cli ... done
Creating stream-sql-demo_kafka_1 ... done
Creating stream-sql-demo_datagen_1 ... done
そうすると、Hue Editor は http://localhost:8888/ にセットアップされます。
同様に、ksqlDB API の実行は次のように行います:
curl http://localhost:8088/info
> {"KsqlServerInfo":{"version":"0.12.0","kafkaClusterId":"DJzUX-zaTDCC5lqfVwf8kw","ksqlServiceId":"default_","serverStatus":"RUNNING"}}
全てを停止するには以下を実行します:
docker-compose down
クエリの体験
ライブSQLは、ベータ版である新しいエディタを必要とすることに注意してください。まもなく、同じエディタのページ上で同時に実行されている複数のステートメントを提供し、より堅牢になることに加えて、ライブ結果グリッドをもたらすようになります。
特に SQL自動補完とEditor 2ですが、更なる改善はまだ道半ばです。将来的には Web Socket を使用する Task Server は別のタスクとして実行し、長時間実行されるクエリが API サーバーでのタイムアウトを防ぐことを可能にします。
注記
既存の Hue Editor をお持ちで ksqlDB を指定したい場合は、この設定変更で有効にしてください:
[notebook]
enable_notebook_2=true
[[interpreters]]
[[[ksqlDB]]]
name=ksqlDB
interface=ksql
options='{"url": "http://localhost:8088"}'
ksql
ksqDB の優れた点の一つは Kafka との密接な統合で、例えば、トピックをリストアップすることができます:
SHOW TOPICS
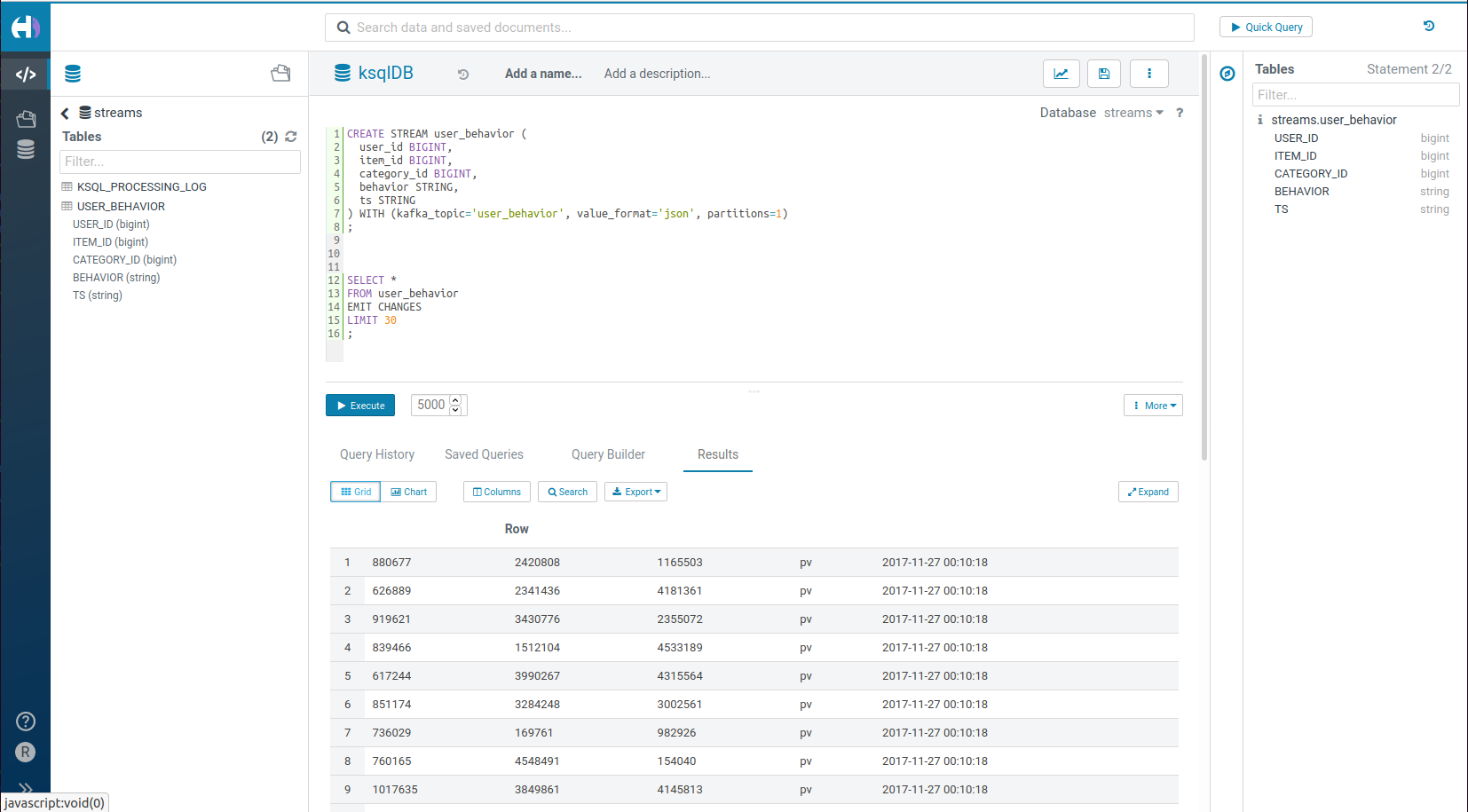
SQL の構文は若干異なりますが、上記のようなテーブルを作成する方法の一つを紹介します:
CREATE STREAM user_behavior (
user_id BIGINT,
item_id BIGINT,
category_id BIGINT,
behavior STRING,
ts STRING
) WITH (kafka_topic='user_behavior', value_format='json', partitions=1)
そして、次のようにして中身をご覧ください:
SELECT *
FROM user_behavior
EMIT CHANGES
LIMIT 30
Hue のエディタ内の別のステートメント、または SQL シェルを起動することにより
docker exec -it ksqldb-cli ksql http://ksqldb-server:8088
独自のレコードを挿入して、結果がライブで更新されるのに気づくこともできます。
INSERT INTO user_behavior (
user_id ,
item_id ,
category_id ,
behavior ,
ts
)
VALUES
(1, 10, 20, 'buy', '1602998392')
次のエピソードでは、importer を介して生のデータストリームから、簡単に直接テーブルを作成する方法をデモします。
ご意見やご質問はありますか?お気軽にこちらにコメントしてください!
これらのプロジェクトは全てオープンソースであり、フィードバックや貢献を歓迎します。HueEditorの場合は Forum や Github issues をご利用ください。
その先へ!
Romain