リアルタイムでのデータクエリは現代の標準になりつつあります。今すぐに決定を下す必要があるときに、翌日や一週間先まで待ちたい人はいないでしょう。
Apache Flink SQL は、現在では、バインド/アンバインドされたデータのストリーム上で SQL を提供するエンジンです。ストリームは様々な ソース から来ることができます。ここでは人気のある Apache Kafka を選びました。
このチュートリアルは、Building an End-to-End Streaming Application (エンドツーエンドのストリーミングアプリケーションを構築する) 素晴らしい FLink SQL のデモに基づいていますが、エンドユーザーのクエリ体験に焦点を当てていきます。
コンポーネント
シンプルにするために、すべてのトピックは “one-click” Docker Compose プロジェクトにまとめられており、これらが含まれています:
- Flink SQL demo からの Flink クラスター
- Flink SQL Gateway - Hue Editor から SQL クエリを投入できるようにする。以前に次のブログで説明しています。SQL Editor for Apache Flink SQL
- Hue Editor - Flink Editor を使用するように設定されています
また、Flinkのバージョンを、1.11.0 から SQL Gateway が必要とする 1.11.1 に移行しました。Flinkは様々なソース (Kafka, MySql, Elastic Search) をクエリすることができるので、イメージにはいくつかの追加のコネクタ依存関係もプリインストールされています。
一行でのセットアップ
設定をフェッチして全てを開始するためのものです:
mkdir stream-sql-demo
cd stream-sql-demo
wget https://raw.githubusercontent.com/romainr/query-demo/master/stream-sql-demo/docker-compose.yml
docker-compose up -d
>
Creating network "stream-sql-demo_default" with the default driver
Creating hue-database ... done
Creating stream-sql-demo_jobmanager_1 ... done
Creating stream-sql-demo_mysql_1 ... done
Creating ksqldb-server ... done
Creating stream-sql-demo_zookeeper_1 ... done
Creating flink-sql-api ... done
Creating stream-sql-demo_taskmanager_1 ... done
Creating hue ... done
Creating ksqldb-cli ... done
Creating stream-sql-demo_kafka_1 ... done
Creating stream-sql-demo_datagen_1 ... done
そうすると、これらの URL が利用できるようになります:
- http://localhost:8888/ Hue Editor
- http://localhost:8081/ Flink Dashboard
同様に、Flink SQL Gateway の実行は次のように行います:
curl localhost:8083/v1/info
> {"product_name":"Apache Flink","version":"1.11.1"}
全てを停止するには以下を実行します:
docker-compose down
クエリの体験
ライブSQLは、ベータ版である新しいエディタを必要とすることに注意してください。まもなく、同じエディタのページ上で同時に実行されている複数のステートメントを提供し、より堅牢になることに加えて、ライブ結果グリッドをもたらすようになります。
特に SQL自動補完とEditor 2ですが、更なる改善はまだ道半ばです。将来的には Web Socket を使用する Task Server は別のタスクとして実行し、長時間実行されるクエリが API サーバーでのタイムアウトを防ぐことを可能にします。
注記
既存の Hue Editor をお持ちで ksqlDB を指定したい場合は、この設定変更で有効にしてください:
[notebook]
enable_notebook_2=true
[[interpreters]]
[[[flink]]]
name=Flink
interface=flink
options='{"url": "http://localhost:8083"}'
Flink SQL
Flink のドキュメント やコミュニティは情報の宝庫です。ここではクエリを始めるための2つの例を紹介します:
- データのモックのストリーム
- Kafka のトピックを通ってくるいくつかの実際のデータ
Hello World
このタイプのテーブルは便利で、自動的にレコードを生成します:
CREATE TABLE datagen (
f_sequence INT,
f_random INT,
f_random_str STRING,
ts AS localtimestamp,
WATERMARK FOR ts AS ts
) WITH (
'connector' = 'datagen',
'rows-per-second'='5',
'fields.f_sequence.kind'='sequence',
'fields.f_sequence.start'='1',
'fields.f_sequence.end'='1000',
'fields.f_random.min'='1',
'fields.f_random.max'='1000',
'fields.f_random_str.length'='10'
)
照会するには次のように行います:
SELECT *
FROM datagen
LIMIT 50
タンブリング
Flink のユニークな点の一つは、時間やオブジェクトのウィンドウに対して SQL クエリを提供していることです。主なシナリオはレコードのローリングブロックをグループ化 して集計を行うことです。
これはより現実的で、Flink SQL のデモから来ています。レコードのストリームは user_behavior Kafka トピックから来ています:
CREATE TABLE user_behavior (
user_id BIGINT,
item_id BIGINT,
category_id BIGINT,
behavior STRING,
ts TIMESTAMP(3),
proctime AS PROCTIME(), -- generates processing-time attribute using computed column
WATERMARK FOR ts AS ts - INTERVAL '5' SECOND -- defines watermark on ts column, marks ts as event-time attribute
) WITH (
'connector' = 'kafka', -- using kafka connector
'topic' = 'user_behavior', -- kafka topic
'scan.startup.mode' = 'earliest-offset', -- reading from the beginning
'properties.bootstrap.servers' = 'kafka:9094', -- kafka broker address
'format' = 'json' -- the data format is json
)
いくつかの生のレコードを突いてみます:
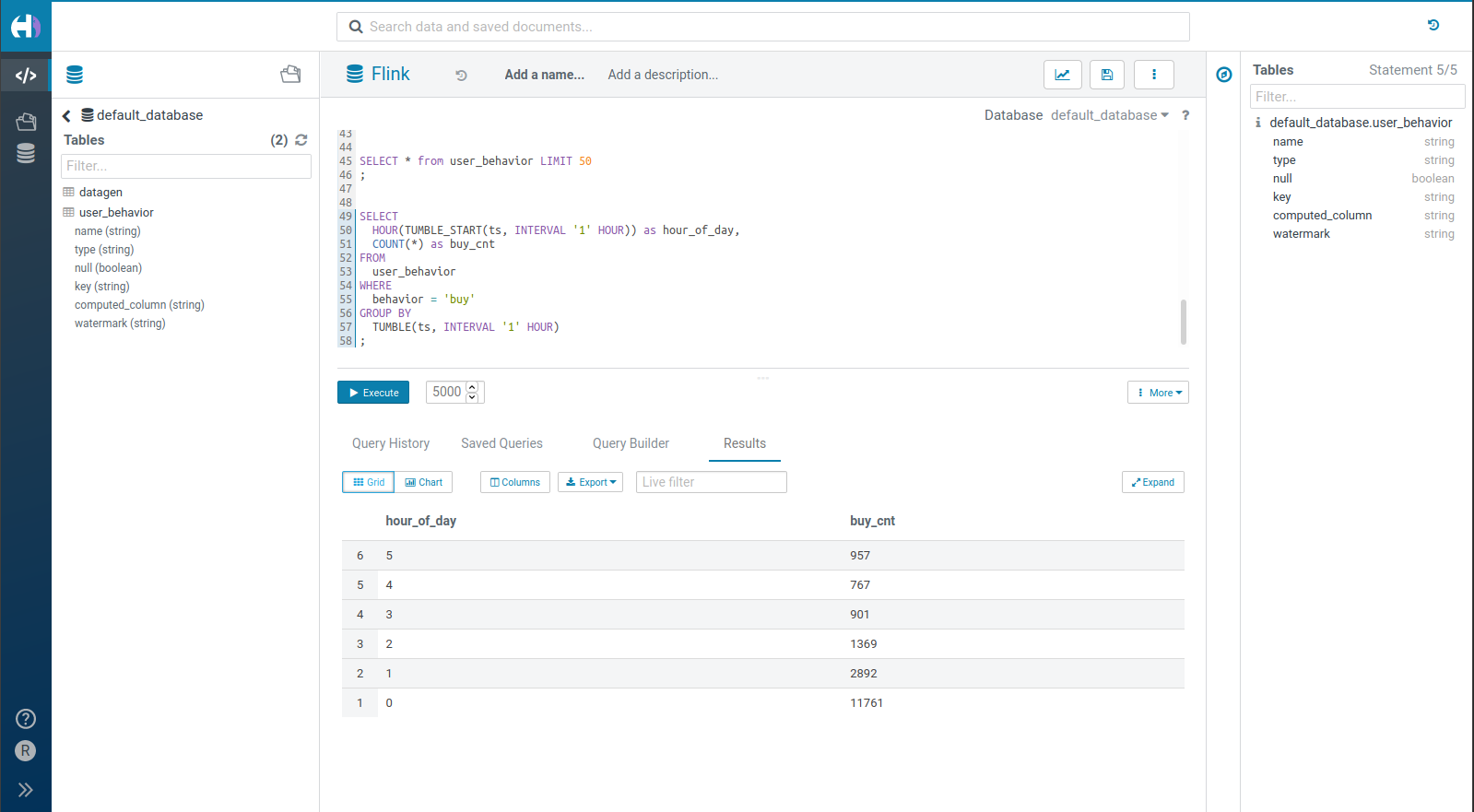
SELECT * from user_behavior LIMIT 50
または、1日の各時間帯に発生している注文数をライブでカウントします:
SELECT
HOUR(TUMBLE_START(ts, INTERVAL '1' HOUR)) as hour_of_day,
COUNT(*) as buy_cnt
FROM
user_behavior
WHERE
behavior = 'buy'
GROUP BY
TUMBLE(ts, INTERVAL '1' HOUR)
次のエピソードでは、importer を介して生のデータストリームから、簡単に直接テーブルを作成する方法をデモします。
ご意見やご質問はありますか?お気軽にこちらにコメントしてください!
これらのプロジェクトは全てオープンソースであり、フィードバックや貢献を歓迎します。HueEditorの場合は Forum や Github issues をご利用ください。
その先へ!
Romain