この記事は、当初 https://medium.com/data-querying/live-sql-querying-live-logs-and-sending-live-updates-easily-e6297150cf92 で公開されました
Flink SQL, ksqlDB, Hue Editor を介した Apache Kafka データストリームからのログ解析チュートリアル
データのストリームに対するリアルタイムクエリは、以前の記事 でデモしたように、強力な分析を行うための現代的な方法です。今回は Web Query Editor で生成された独自のログをクエリすることで、よりパーソナライズされたシナリオを見ていきます。
まず、以降で紹介するオープンソースプロジェクト、特にFlink Version 1.12 、SQL gateway そして同じくHue Editor の改善のための全てのコミュニティに感謝します。 目標は、現在の SQL の機能と、データのストリームでの対話的なクエリを構築する際の使いやすさをデモすることです。
Flink SQL と ksqlDB によるデータログストリームのクエリ
アーキテクチャー
この記事にはライブデモのセットアップ手順があるので、ローカルで簡単に試せるようになっています。
Hue Editor からの生ログ..
[29/Dec/2020 22:43:21 -0800] access INFO 172.21.0.1 romain - "POST /notebook/api/get_logs HTTP/1.1" returned in 30ms 200 81
.. これはFluentd を使って収集され、access/INFO 以外の行をフィルタリングした後、Kafka のトピックに直接forward されます(データをシンプルに保つため)。
{"container_id":"7d4fa988b26e2034670bbe8df3f1d0745cd30fc9645c19d35e8004e7fcf8c71d","container_name":"/hue","source":"stdout","log":"[29/Dec/2020 22:43:21 -0800] access INFO 172.21.0.1 romain - \"POST /notebook/api/get_logs HTTP/1.1\" returned in 30ms 200 81"}
その後データは Kafka のトピックから抽出され、ログインしたユーザーごとに 10 秒間のローリングウィンドウ で何回 API コールが行われているかを計算する、長時間実行されるクエリに変換される前に対話的に分析されます。
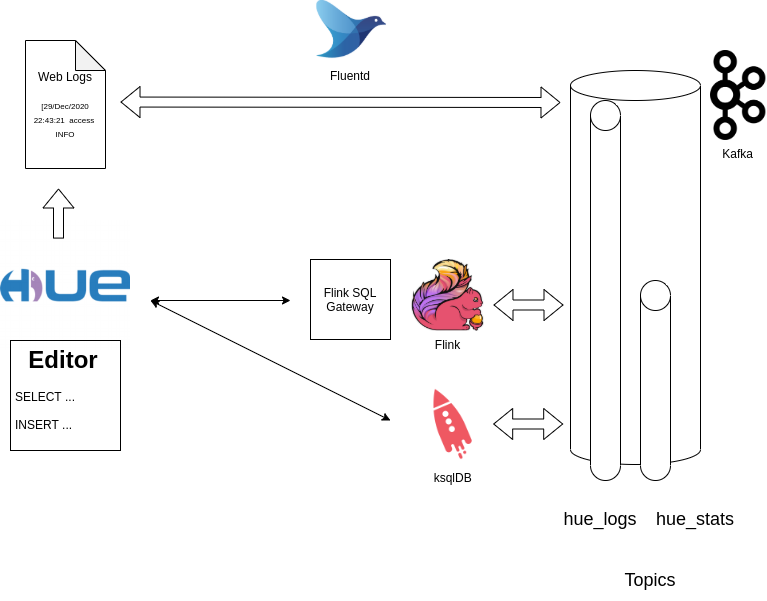
ライブストリーム分析のアーキテクチャー
デモ
Docker Compose の設定 を取得して全てを開始します:
mkdir stream-sql-logs
cd stream-sql-logs
wget https://raw.githubusercontent.com/romainr/query-demo/master/stream-sql-logs/docker-compose.yml
docker-compose up -d
>
Creating network "stream-sql-logs_default" with the default driver
Creating hue-database ... done
Creating stream-sql-logs_jobmanager_1 ... done
Creating stream-sql-logs_fluentd_1 ... done
Creating stream-sql-logs_zookeeper_1 ... done
Creating ksqldb-server ... done
Creating hue ... done
Creating stream-sql-logs_taskmanager_1 ... done
Creating flink-sql-api ... done
Creating stream-sql-logs_kafka_1 ... done
その後、これらの URL が利用可能になります:
- http://localhost:8888/ Hue Editor
- http://localhost:8081/ Flink Dashboard
全てを止めるには以下のようにします:
docker-compose down
シナリオ
Web Editor とやりとりしている間にウェブログが生成されています。それらのサブセットを、Flink SQLを介してクエリする Kafka トピックに取り込みます。ksqlDB は、1日の終わりに全ての SQL のSELECTとINSERTが標準の Kafka トピックを通過していることを証明するために使用されます。
もう一度 TUMBLE 関数を使用して、簡単に集計のライブウィンドウを作成します。
ユーザー名によるグループ化を表示するために、二人の別々のユーザー(‘demo’ と ‘romain’) としてログインしました。
Flink の目新しさの一つは新しいUPSERT into Kafka コネクターで、ローリング集計したデータを Kafka に送り返すことができるようになります。これにより、トピックから単純に読み取ることができるレポーティングやアラートシステムによって、さらに下方での消費が可能になります。
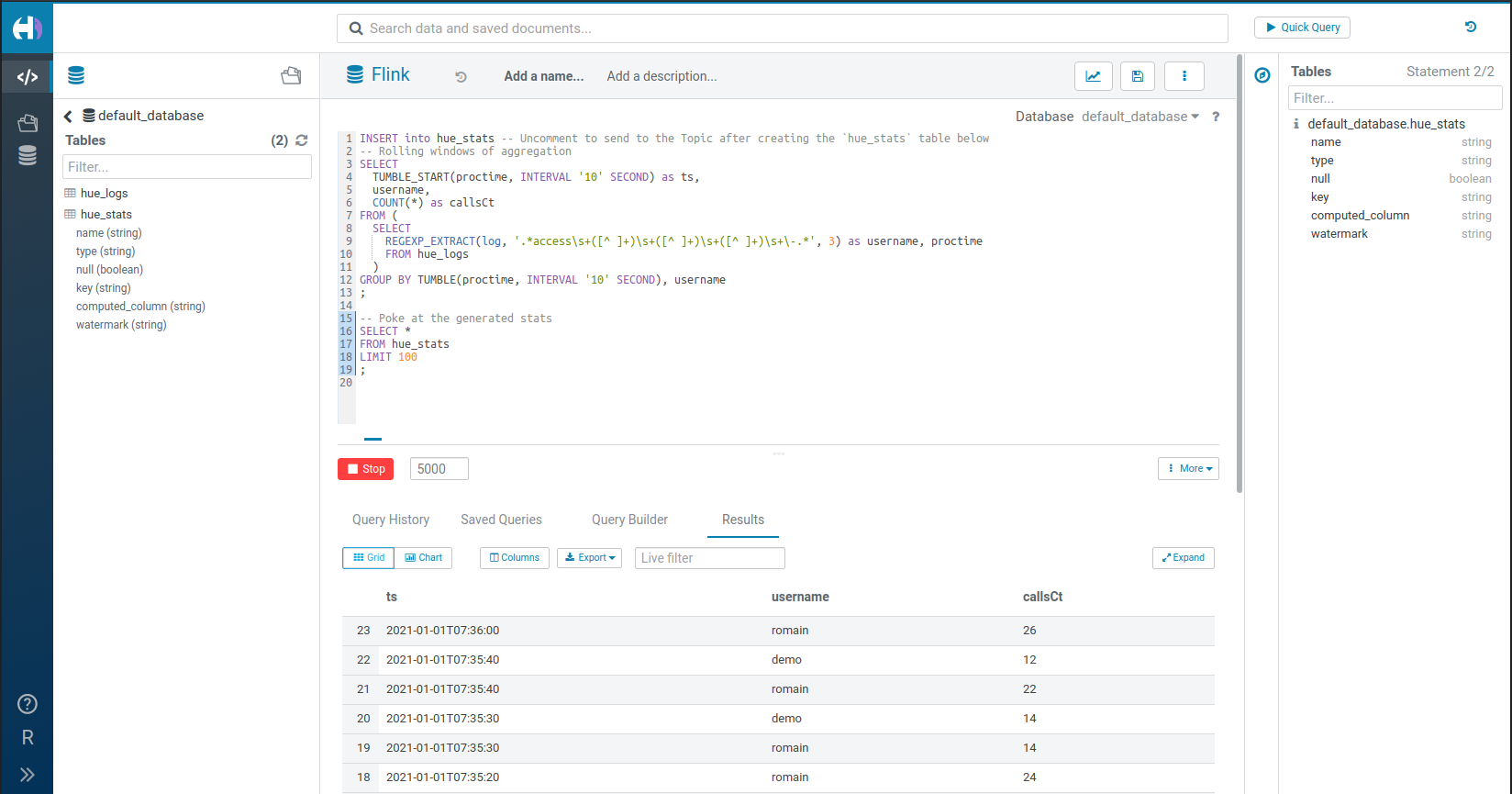 ライブ統計のローリングウィンドウを計算して Kafka のトピックに挿入する
ライブ統計のローリングウィンドウを計算して Kafka のトピックに挿入する
追記すると、実際の日付とHTTPコードのフィールドを抽出したり、カウントがある閾値を超えた/超えなかった時にアラートメッセージを出力することでより精細にクエリを行うことができ、その上にライブアプリケーション を構築するのに最適です。
エディタの優れた点の一つは、REGEXP_EXTRACT, DATE_FORMAT などのSQL関数 をインタラクティブにいじることができることです。
SQL
こちらが Query Editor で入力した SQL ソースです。
Et voila! (さぁ、どうぞ!)
フィードバックや質問はありますか?お気軽にこちらまでコメントお願いします!
これらのプロジェクトも全てオープンソースであり、フィードバックや貢献を歓迎します。
Hue Editor の場合は、フォーラム や Github issues がその良い場になっています。より洗練されたSQL自動補完やコネクタ、Web Socket、Celery Task serverとの統合が改善策として挙げられています。
前に進みましょう!
Romain