データクランチャーズの皆さん、こんにちは
SQL クエリをもっと簡単に実行したいと思っていませんか?ここでは、次の Hue のリリースで予定されている様々なクエリの改善点を紹介します!
新しいデータベース
Hue は、Apache Phoenix, Apacke Flink SQL、 および Apache Spark SQL (Apache Livy 経由) により、より洗練された経験を積んでいます。
Apache Phoenix
Apache Phoenix は、SQL を介して Apache HBase データベースに簡単にクエリができるようにします。現在、この統合は完全に動作しており、いくつかのコーナーケース(例えば、デフォルトの Phoenix データベースの扱い、左側のアシストでのテーブルと列の一覧、なりすましのサポートなど…) が修正されています。
Apache Flink SQL
データストリームへのSQL クエリ のための Apache Flink のサポートは成熟してきており、エディタとの最初の統合も行われています。
注 KsqlDB のサポートも同様の機能を共有(ライブクエリと結果グリッド)しているため、進展しています。
Apache SparkSql
SparkSql は非常に人気があり、Apache Livy を介して SQL クエリを実行する際の改善がなされています。従来の SqlAlchemy コネクタ や HiveServer Thrift も動作していることにご注意ください。
UDF / 関数
動的一覧
エディタには全ての関数が一覧されているわけではありません。(セッションや企業レベルで登録されているもの、Hue のリリース後に作成されたもの、不足しており追加可能なものなど…)
現在、エディタはデータベースに関数の完全なリストを問い合わせ、不足している関数を General セクションに追加します。
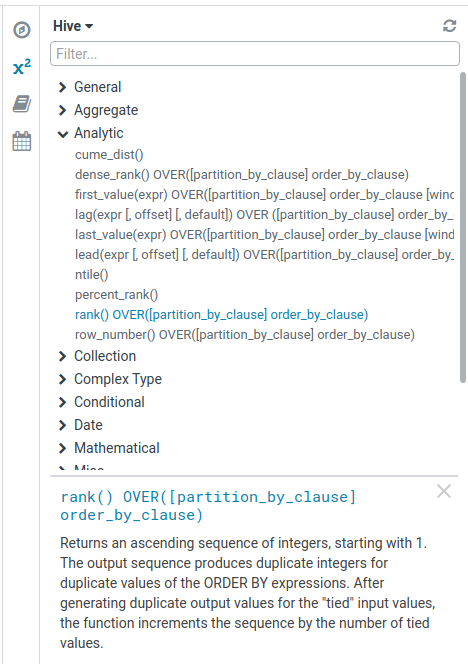
引数
引数の位置関係が理解できるようになり、人気のある関数の定数の引数も利用できるようになりました。例えば、引数の2番目の位置の日付変換のためのフォーマットがユーザーに提示されるようになりました。
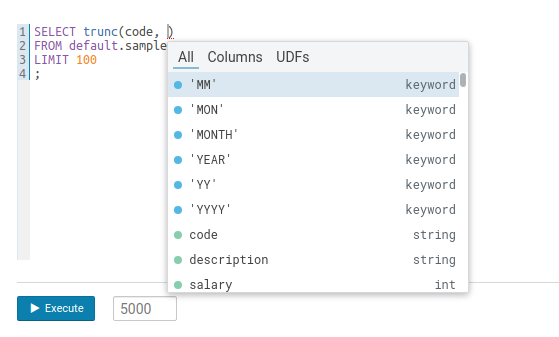
自動補完
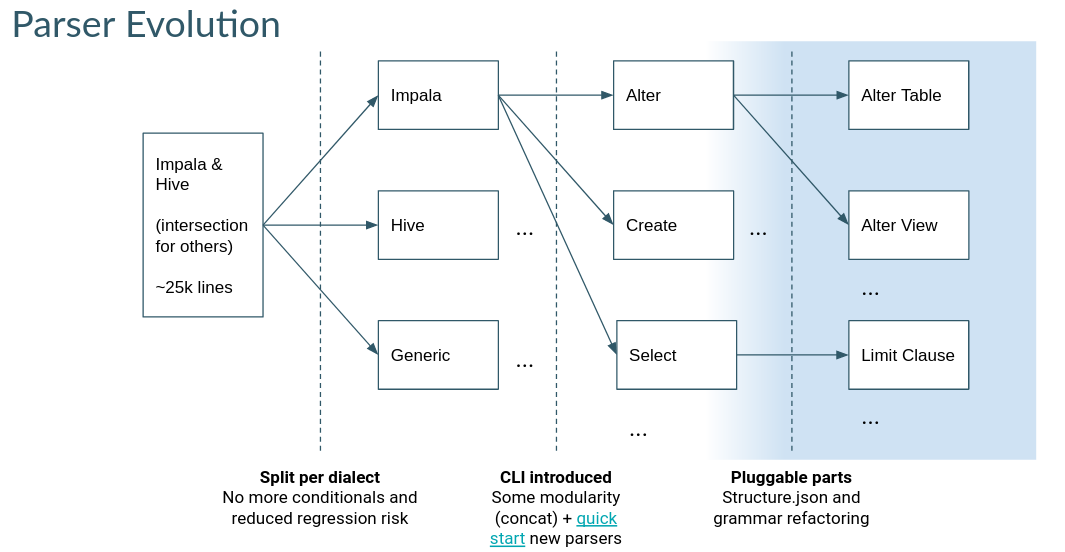
独自のパーサーを開発
パーサーは Apache Calcite SQL サブセットをサポートすることを第一の目標とし、より小さな再利用可能なピース structure.json で抽出されています。Parser SDK にはより詳細な情報があります。
例えば、structure.json は SQL パーサー全体で再利用可能な一般的な文法と特殊な文法のピースで構成されています。
structure.json
[...],
"../generic/select/select.jison",
"../generic/select/select_conditions.jison",
"select/select_stream.jison",
"../generic/select/union_clause.jison",
"../generic/select/where_clause.jison",
[...]
select_stream.jison
SelectStatement
: 'SELECT' 'STREAM' OptionalAllOrDistinct SelectList
;
SelectStatement_EDIT
: 'SELECT' 'STREAM' OptionalAllOrDistinct 'CURSOR'
{
if (!$3) {
parser.suggestKeywords(['ALL', 'DISTINCT']);
}
}
;
独立した大きなパーサーを構築するというスケーラブルではないという戦略から、文法操作を共有するパーサーを構築するという戦略へと移行しています。
スケジュールされた Hive クエリ
Hive 4 は SQL 構文によるスケジューリングクエリをネイティブにサポートしています。
* create
create scheduled query Q1 executed as joe scheduled '1 1 * * *' as update t set a=1;
* change schedule
alter scheduled query Q1 cron '2 2 * * *'
* change query
alter scheduled query Q1 defined as select 2
* disable
alter scheduled query Q1 set disabled
* enable
alter scheduled query Q1 set enabled
* list status
select * from sysdb.scheduled_queries;
* drop
drop scheduled query Q1
なお HUE-3797 にはミニ UI が付属しており、クエリの監視やスケジューリングが2回クリックするだけでできるようになります。(右のアシストパネルを参照)
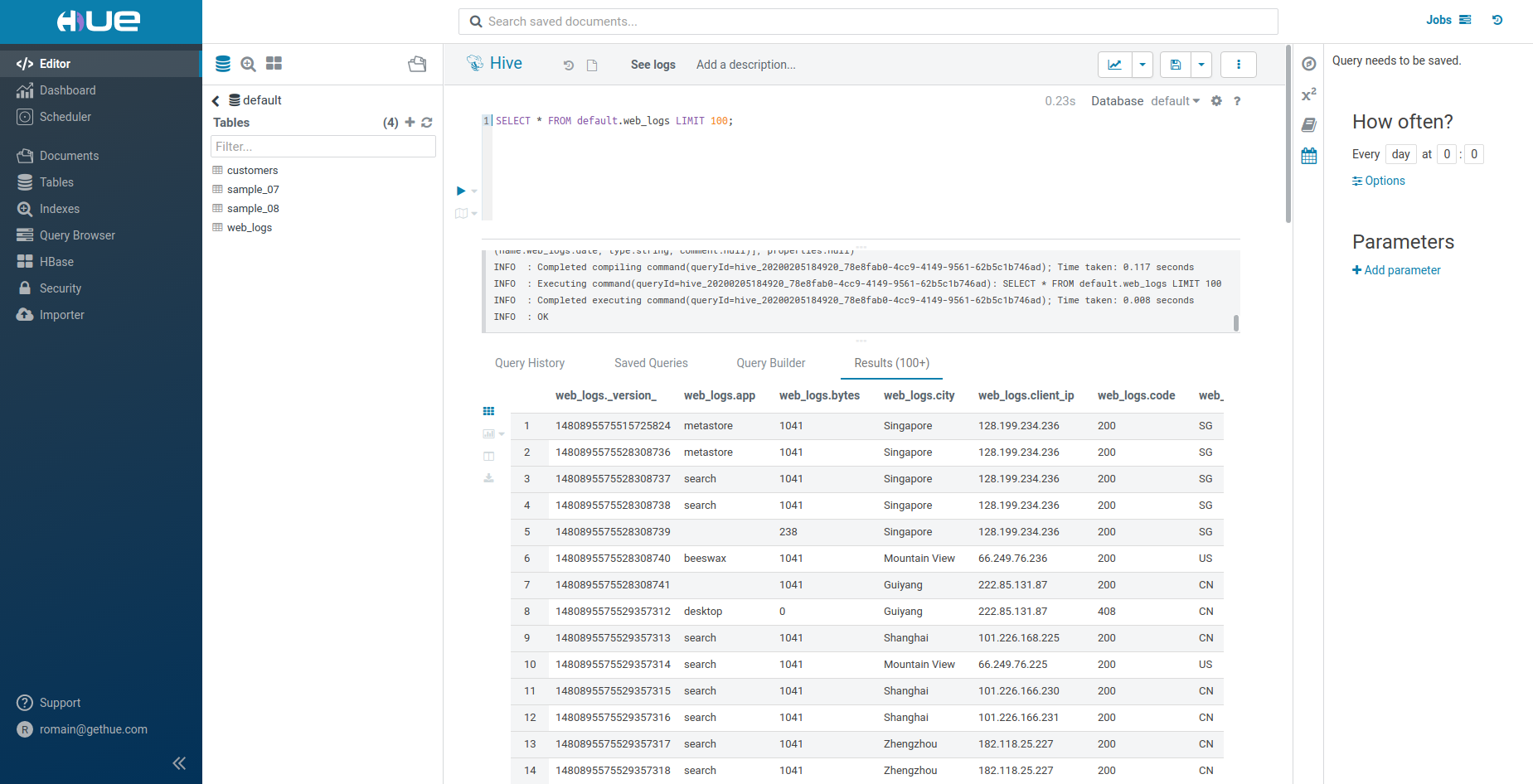
Limit Nの自動補完
自動補完の際に ‘LIMIT’ を追加すると、実際のサイズも提案されるようになりました。
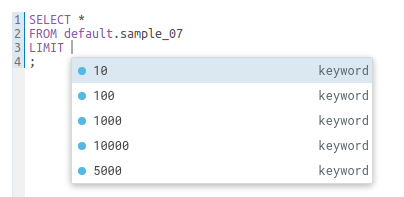
列キーのアイコン
列の値が別のテーブルの別の列を指している場合、外部キーを表示するための追加アイコンが利用できます。
![]()
CREATE TABLE person (
id INT NOT NULL,
name STRING NOT NULL,
age INT,
creator STRING DEFAULT CURRENT_USER(),
created_date DATE DEFAULT CURRENT_DATE(),
PRIMARY KEY (id) DISABLE NOVALIDATE
);
CREATE TABLE business_unit (
id INT NOT NULL,
head INT NOT NULL,
creator STRING DEFAULT CURRENT_USER(),
created_date DATE DEFAULT CURRENT_DATE(),
PRIMARY KEY (id) DISABLE NOVALIDATE,
CONSTRAINT fk FOREIGN KEY (head) REFERENCES person(id) DISABLE NOVALIDATE
);
サンプルのポップアップでは、リレーションシップのナビゲートもサポートされるようになりました。
ERD テーブル
列と外部キーのリンクを視覚的に一覧表示することで、SQL クエリを作成する際のスキーマと関係をより早く理解することができます。ドキュメントページのライブデモをぜひご覧ください。
注 新しい共有可能なコンポーネントシステムについては、今後のブログ記事で詳しく紹介する予定です。
スマートな提案
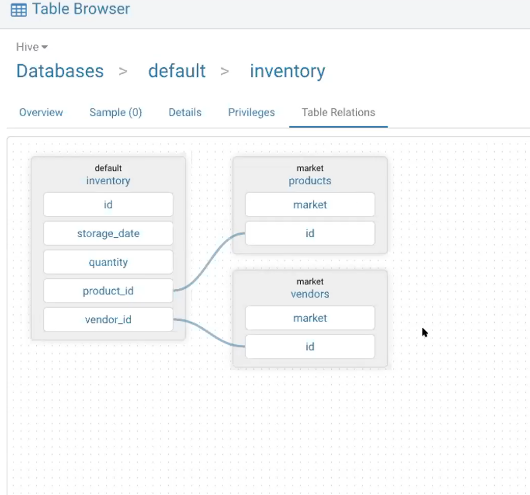
ローカルアシスタントは、JOIN の自動補完の提案や、単純なリスクアラート(例えば LIMIT 節の欠落など)を提供します。
これはベータ機能です。有効にするには hue.ini で次のようにします。
[medatata]
[[optimizer]]
# Requires Editor v2
mode=local
インポーター
新しい SQL テーブルの作成が簡単になるように、データインポートウィザードでいくつかの修正を行いました。以前の記事で詳しくご覧いただけます。
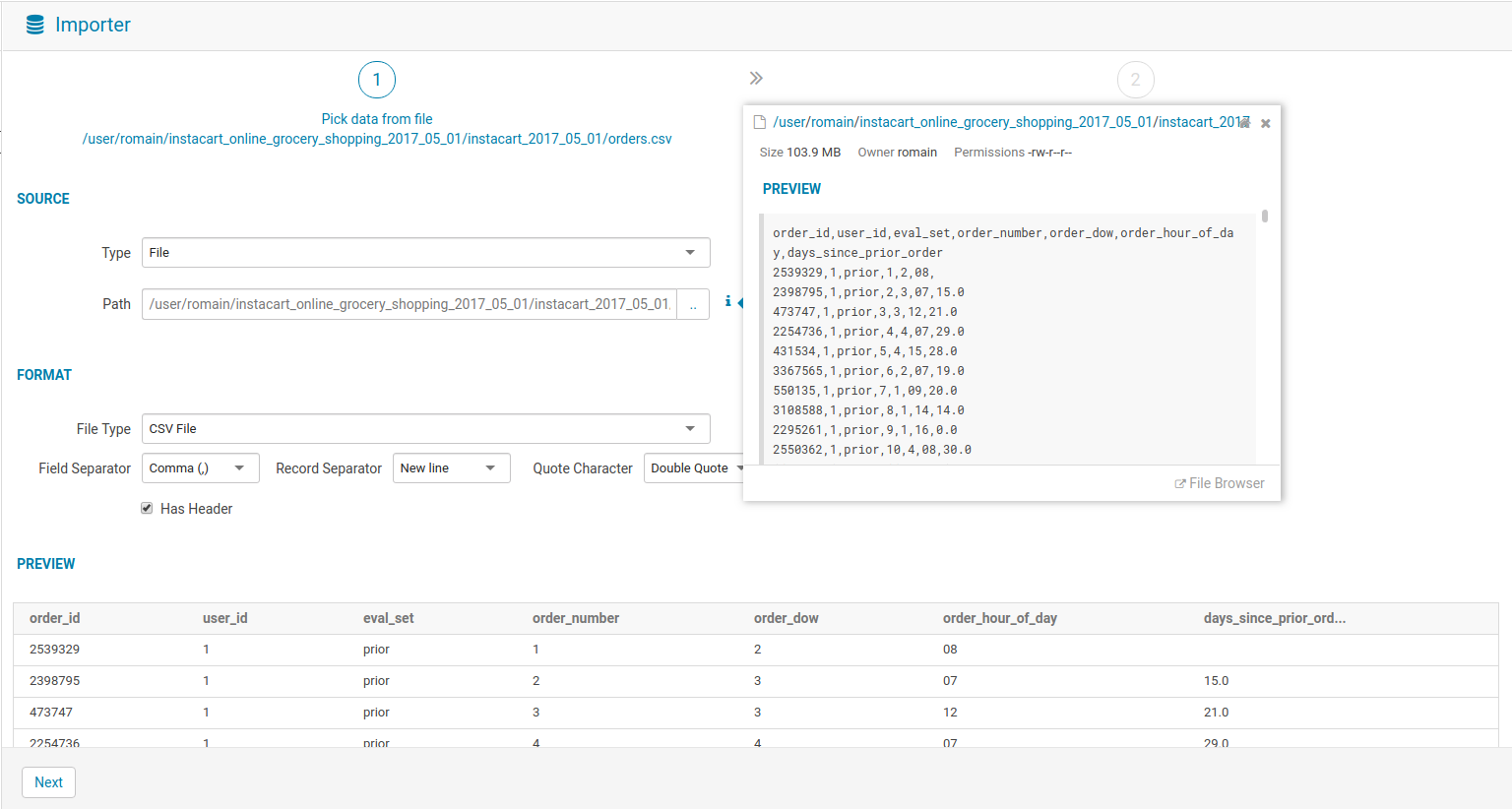
コネクタ付きエディタv2
これらはベータ版の機能であり、まだかなりの量の研鑽が必要ですが、十分に安定しているので多くのユーザーに試していただきフィードバックを送っていただきたいと考えています。
クエリの事項はより良い安定性と複数のクエリを同時に実行できるように置き換えられています。新しいバージョンの詳細はベータ後に公開予定です。
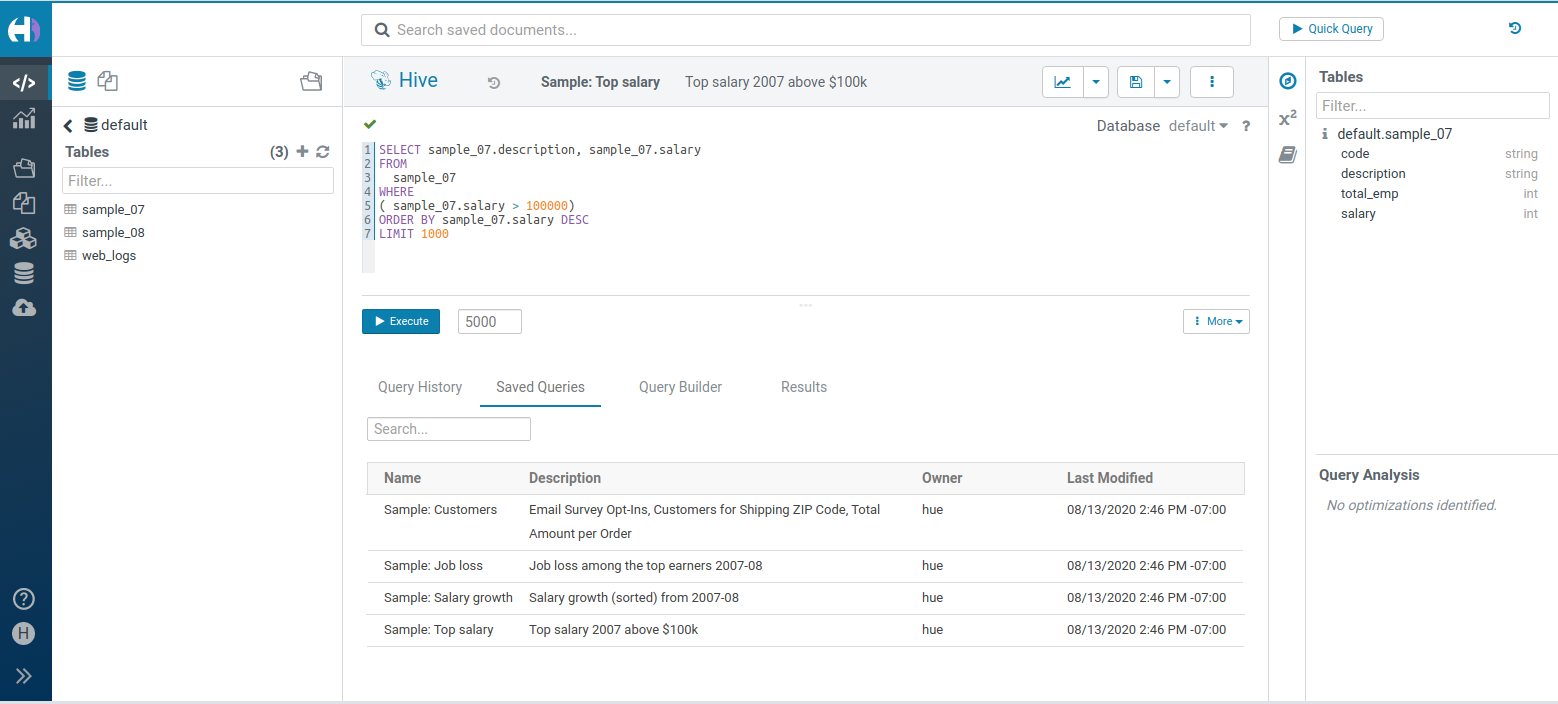
hue.ini で有効にする方法は次のとおりです。
[notebook]
enable_notebook_2=true
[desktop]
enable_connectors=true
注 https://demo.gethue.com/ では新しいエディタが有効になっています。
フィードバックや質問はありますか?このページや Forum にコメントください。quick start すぐに SQL のクエリを始められます!
その先へ!
Romain from the Hue Team