Spark SQL
Spark SQL は、Spark アプリ内にクリーンなデータクエリーのロジックを埋め込むのに便利です。Hue には便利なエディタが付属しているので、SQL スニペットの開発が簡単になります。
ドキュメントに記載されている通り、Spark SQL はさまざまなコネクターが一緒になっています。ここでは Livy を紹介します。
Apache Livy は実行中の Spark インタープリターへのブリッジを提供するので、SQL、pyspark、scala のスニペットを対話的に実行できるようにします。
hue.ini で、API の URL を設定します。
[spark]
# The Livy Server URL.
livy_server_url=http://localhost:8998
そしていつものように、設定したインタープリターを確認してください。
[notebook]
[[interpreters]]
[[[sparksql]]]
name=Spark SQL
interface=livy
そうすることで、エディターが表示されます。
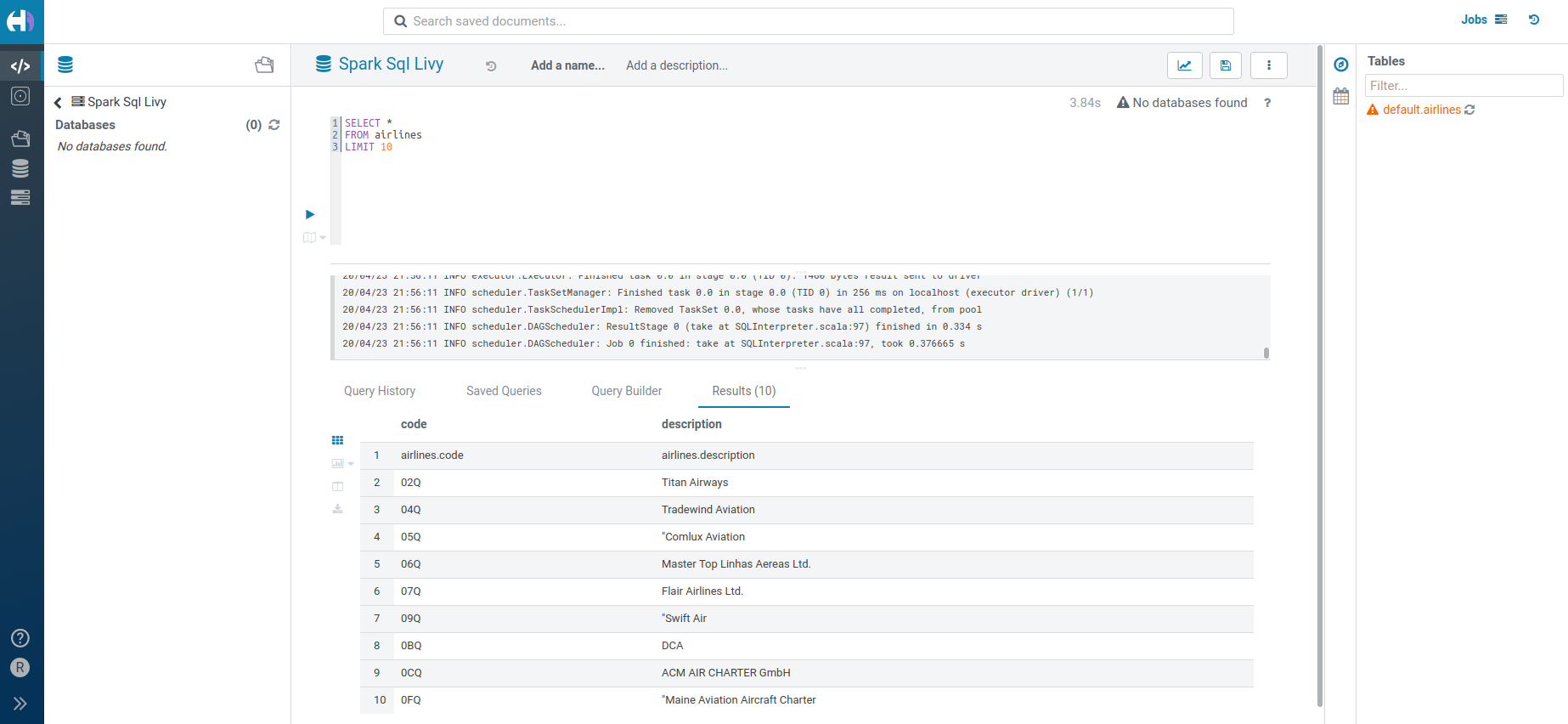
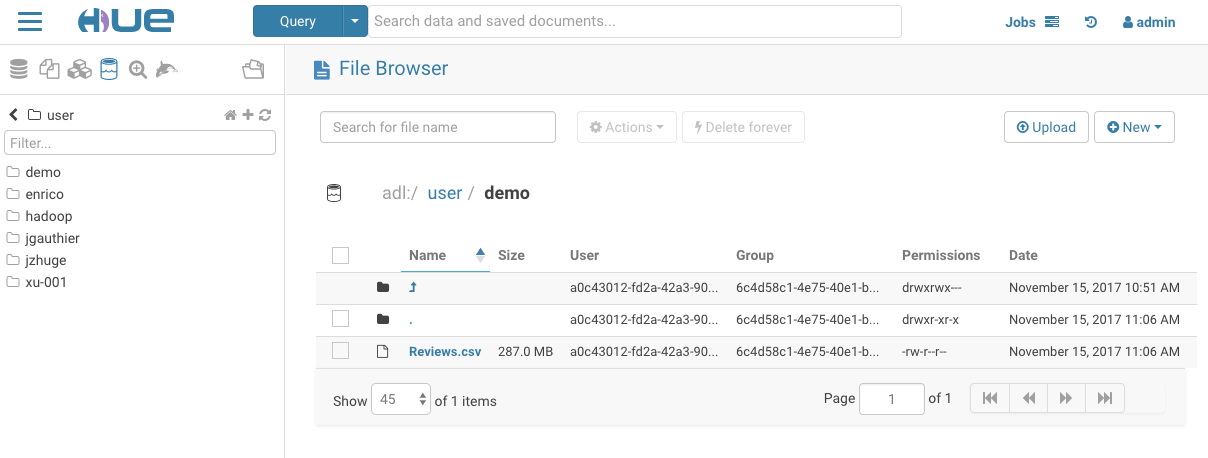
Hue を使用する利点の一つは、HDFS / S3 / Azure 用のファイルブラウザー と、完全なセキュリティ(KerberosとKnox IdBroker の統合を介して実際のユーザーの資格情報を使用することさえも)です。
今後の改善点を紹介します。
- データベース/テーブル/列の自動補完は現在空です
- SQL文法の自動補完は拡張できます
- ミニSQLエディターのポップアップを可能にするSQL Scratchpad モジュールは現在進行中です
フィードバックやご質問はありますか?こちら、またはフォーラム and quick start で気軽にコメントして、SQLクエリのクイックスタートをしましょう!
Romain from the Hue Team