ウェブブラウザで Spark SQL を素早く記述、実行します。
この記事は、当初 https://medium.com/data-querying/a-sparksql-editor-via-hue-and-the-spark-sql-server-f82e72bbdfc7 で公開されました
Apache Spark は データを扱う(wrangling)/準備するために、特にデータ操作プログラムを宣言的でシンプルに保つように、SQL スニペットを埋め込む場合に人気があります。
一つの良いニュースは、SQL の構文が Apache Hive に非常に似ているので、Hue の非常に強力な Hive の自動補完が非常にうまく機能するということです。
ここでは、すでにあなたのスタックで利用できるようになっているかもしれない Spark SQL Thrift Server のインターフェイスと統合する方法を説明します。
記事にはワンクリックデモのセットアップが付属しています。シナリオはかなりシンプルで、バッチクエリについては、より多くのライブデータのために特化したフォローアップのエピソードで紹介する予定です。
Docker Compose の設定 をフェッチして全てを開始するためには次のように行います:
mkdir spark
cd spark
wget https://raw.githubusercontent.com/romainr/query-demo/master/spark/docker-compose.yml
docker-compose up -d
>
Creating network "spark_default" with the default driver
Creating hue-database ... done
Creating livy-spark ... done
Creating spark-master ... done
Creating spark-sql ... done
Creating hue ... done
その後、これらの URL が利用可能になります:
- http://127.0.0.1:8080/ Spark Master Web UI
- http://127.0.0.1:4040/environment/ Thrift SQL UI
- http://127.0.0.1:7070 Spark Master
- http://localhost:8998 Livy REST Server
全てを停止するには次のようにします:
docker-compose down
Hello World
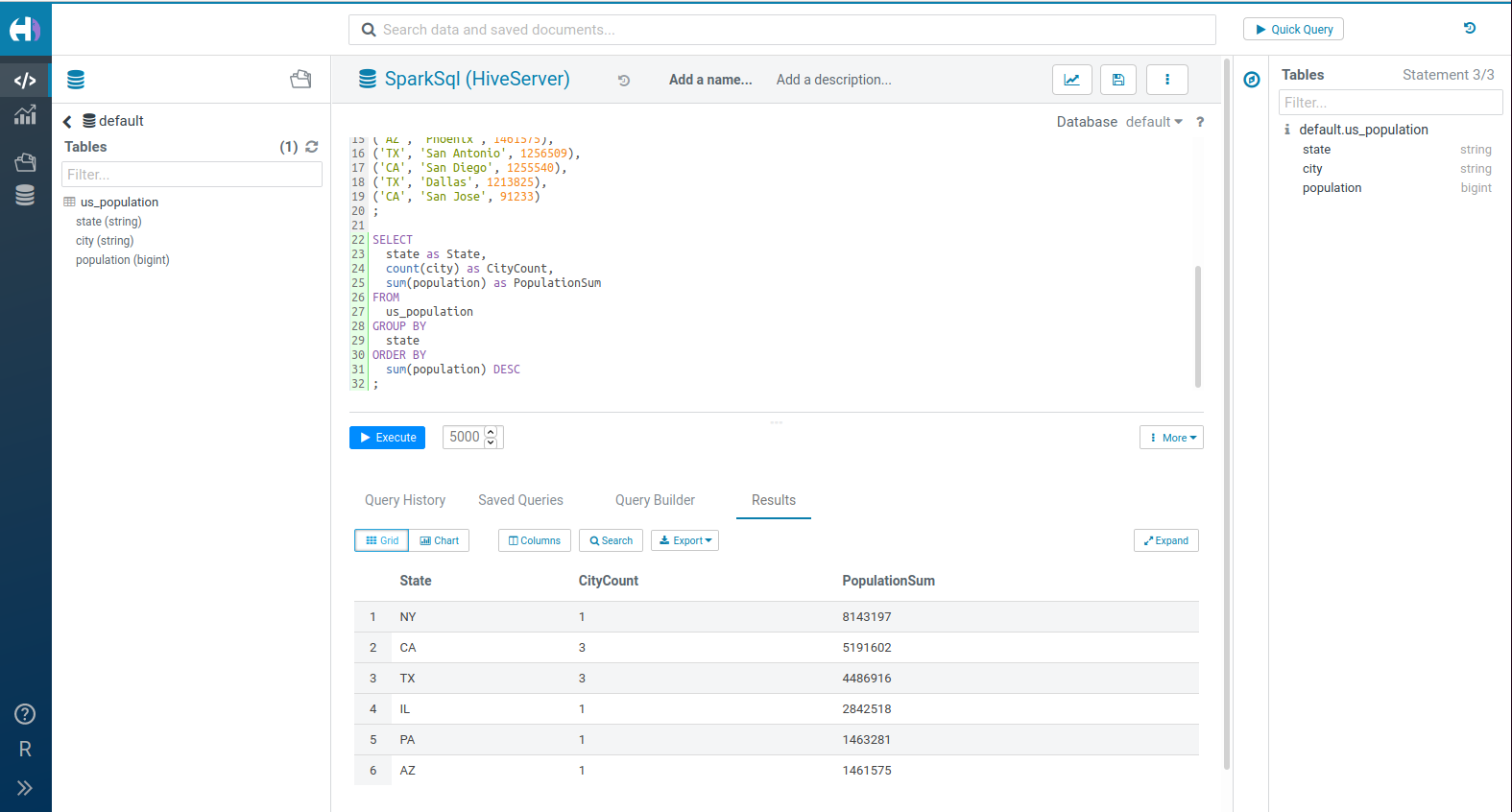
いくつかの都市と住民数を表す SQL のテーブルを作成する方法:
CREATE TABLE IF NOT EXISTS us_population (
state CHAR(2),
city VARCHAR(20),
population BIGINT
)
;
INSERT INTO us_population
VALUES
('NY', 'New York', 8143197),
('CA', 'Los Angeles', 3844829),
('IL', 'Chicago', 2842518),
('TX', 'Houston', 2016582),
('PA', 'Philadelphia', 1463281),
('AZ', 'Phoenix', 1461575),
('TX', 'San Antonio', 1256509),
('CA', 'San Diego', 1255540),
('TX', 'Dallas', 1213825),
('CA', 'San Jose', 91233)
;
SELECT
state as State,
count(city) as CityCount,
sum(population) as PopulationSum
FROM
us_population
GROUP BY
state
ORDER BY
sum(population) DESC
;
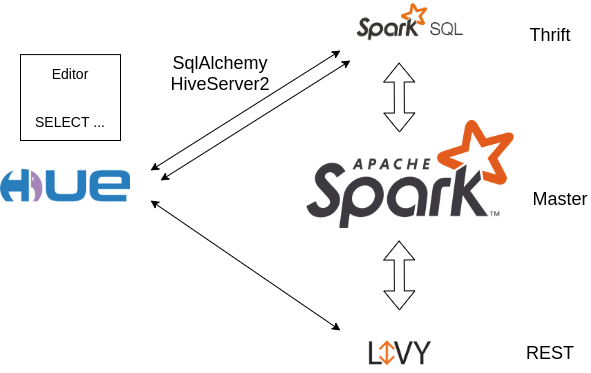
Spark SQL Server と接続するためのインターフェースは?
以前、Hue 経由で Spark SQL を送るために Apache Livy を利用する方法をデモしました。その際にも詳しく説明しましたが、Livy は当初 Hue プロジェクト内で作成されたもので、PySpark / Scala Spark /SparkSql ステートメントをインタラクティブに、またはバッチで軽量に送信することができます。
しかし、Spark に搭載されている Distributed SQL Engine (別名 “Thrift Server “として知られています)よりも公式なものではないように見えるかもしれないという欠点があります。
Hue は2つのインターフェースを介してSpark SQL Thrift Serverに接続することができます:
- SqlAlchemy: universal Python ライブラリをベースにしたコネクタ
- HiveServer2: Hue の Hive 用のネイティブなコネクタ
長い話を短くまとめると、SqlAlchemy の主な利点は、より多くの SparkSql の問題を解決できることですが、クエリは同期的に送信されます (つまり、Hue Task Server が設定されていない限り、数秒以上のクエリは進捗報告がなく、長いクエリはタイムアウトします)。
そのため、SqlAlchemy を使い始めることをお勧めしますが、よりネイティブ/高度な HiveServer2 API で小さな修正を報告/貢献することをお勧めします。
注: SqlAlchemyのインターフェースは Hive コネクタを必要としますが、これは #150 の問題のため、そのままでは動作しません。しかし、Hueに同梱され、わずかにパッチを当てたモジュールが動作することを示しています: https://github.com/gethue/PyHive
設定
hue.ini でコネクタを設定し、ドキュメントにあるように PyHive コネクタがインストールされていることを確認します。
[notebook]
[[interpreters]]
[[[sparksql-alchemy]]]
name=SparkSql (via SqlAlchemy)
interface=sqlalchemy
options='{"url": "hive://localhost:10000/default"}'
[[[sparksql]]]
# Must be named 'sparksql', hostname and more options are
# in the 'spark' section
name=SparkSql (via HiveServer2)
interface=hiveserver2
[spark]
sql_server_host=localhost
sql_server_port=10000
次回は何でしょうか?
これで完成です!
次回は SparkSQL の組み込み筋ペットを簡単に編集し素早くテストできる Hue の SQL Scratchpad コンポーネントの進捗状況や、ライブでーたをクエリする方法について説明します。
その先へ!
Romain