HBaseのようなビッグテーブルにあるライブのKafkaデータをSQLで簡単にクエリする
この記事は、当初 https://medium.com/data-querying/phoenix-brings-sql-to-hbase-and-let-you-query-kafka-data-streams-8fd2edda1401 で公開されました
Apache HBase はビッグテーブルファミリーの、大規模なキーバリューデータベースです。ランダムな読み書きに優れ、分散型です。Hue Query アシスタントは、組織内でのデータベース検索を容易にし、ユビキタスなものにすることを目的とした、汎用性の高いSQL を作成する Web アプリケーションです。
この記事では、HBase に SQL インターフェイス層を提供する Apache Phoenix 最近の統合をデモします。これにより、クエリを簡単に行うことができます。Hue は、既にネイティブアプリケーションを介したHBaseへのクエリをサポートしていますが、SQL の優れた点は、その人気(多くの人がSQLの基礎を知っている)と、Hue Editor の強力な能力を利用できることです。
典型的なユースケースは、リアルタイムの分析やクエリを実行するために、メトリクス、トレース、ログなどのライブデータをインジェストすることです。ここでは、古典的な “Hello World " を用いてデモを行い、次にKafkaを使ったライブログのインジェストを行います。
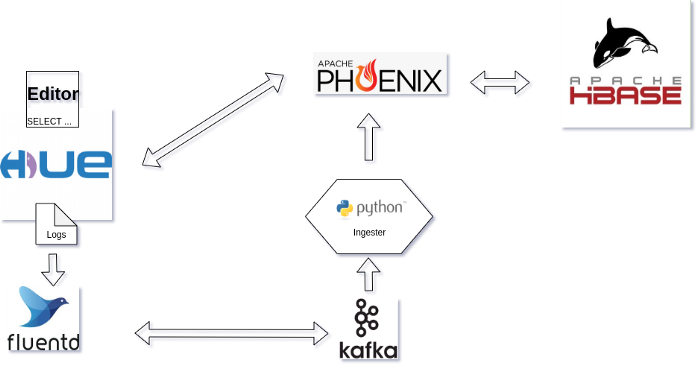
1クリックで自分でテストできるように、Docker compose 環境を開発しました。以下のサービスが含まれています。
- HBase
- Phoenix Query Server
- Hue Query Assistant (Phoenix connector が付属しています)
- Fluentd - Kafka に Hue のログをライブでインジェスとします
- Python Ingester スクリプトは Kafka からログを消費(consume)してHBaseにプッシュします
次は Docker Composeの設定を取得して、すべてを起動するためのものです:
mkdir big-table-hbase
cd big-table-hbase
wget https://raw.githubusercontent.com/romainr/query-demo/master/big-table-hbase/docker-compose.yml
docker-compose up -d
>
Creating hue-database ... done
Creating query-demo_zookeeper_1 ... done
Creating hbase-phoenix ... done
Creating query-demo_fluentd_1 ... done
Creating query-demo_kafka_1 ... done
Creating hue ... done
Creating kafka2phoenix ... done
そうすると、これらの URL が利用できます:
- http://localhost:8888/ Hue Editor
- http://localhost:8765/ Phoenix Query Server
全てを停止するには次のように行います:
docker-compose down
Hello World
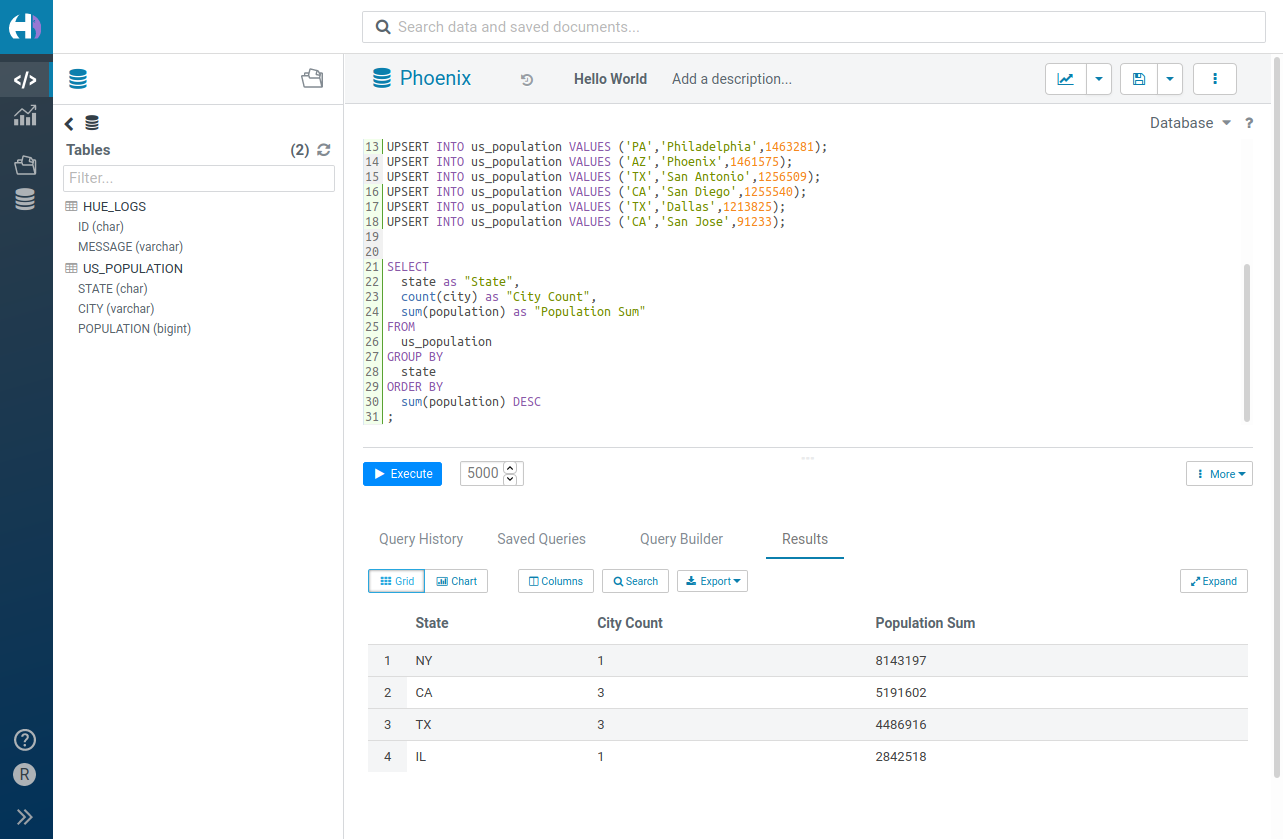
このケースでは、公式のチュートリアル (Get started in 15 minutes tutorial) に従うだけです。
CREATE TABLE IF NOT EXISTS us_population (
state CHAR(2) NOT NULL,
city VARCHAR NOT NULL,
population BIGINT
CONSTRAINT my_pk PRIMARY KEY (state, city)
);
UPSERT INTO us_population VALUES ('NY','New York',8143197);
UPSERT INTO us_population VALUES ('CA','Los Angeles',3844829);
UPSERT INTO us_population VALUES ('IL','Chicago',2842518);
UPSERT INTO us_population VALUES ('TX','Houston',2016582);
UPSERT INTO us_population VALUES ('PA','Philadelphia',1463281);
UPSERT INTO us_population VALUES ('AZ','Phoenix',1461575);
UPSERT INTO us_population VALUES ('TX','San Antonio',1256509);
UPSERT INTO us_population VALUES ('CA','San Diego',1255540);
UPSERT INTO us_population VALUES ('TX','Dallas',1213825);
UPSERT INTO us_population VALUES ('CA','San Jose',91233);
SELECT
state as "State",
count(city) as "City Count",
sum(population) as "Population Sum"
FROM
us_population
GROUP BY
state
ORDER BY
sum(population) DESC
;
Kafka のデータのストリームをクエリする
デモをより現実的なものにするために、Kafka トピックにインポートされたライブデータをクエリします。データは SQL Editor 自体のアクセスログで構成されています (つまり、Hue の使用状況のメタデータ分析を行っているのです ;)。実際には、これは顧客の注文、天気、株価、トラフィックデータなど、他の種類のデータであっても構いません。
ものごとをシンプルに保つために、小さな ingester プログラムを使って、Kafka からデータを読み込んで HBase にプッシュすることで、クエリを実行してライブの結果を見ることができるようにしています。Phoenix Kafka Consumer、Apache Nifi、Apache Spark、Fluentd…など、本番環境でこれを実行するための多くのツールがあります。
このケースでは、Kafka のトピック
hue_logs
を、kafka-python モジュールで読み、Phoenix テーブルを作成したあとで Phoenix Python モジュールで UPSERT 文を送信して Kafka のレコードをテーブルに挿入しています。
CREATE TABLE hue_logs (
id CHAR(30) PRIMARY KEY,
message VARCHAR
)
UPSERT INTO hue_logs VALUES
(<timestamp of record + id>, <log message>)
アーキテクチャの図では、ingester/Fluentd/Kafkaをソリューションに置き換えています。そして、HBase に格納されている Hue サービスの最新のアクセスログを見るためには、Phoenix テーブルの hue_logs に数回クエリを実行するだけです。
SELECT *
FROM hue_logs
ORDER BY id DESC
LIMIT 100
これで完成です!
コミュニティとPhoenix/HBase チームに感謝します。特に、better SQL autocomplete, create table wizard 用のコネクタ、いくつかの組み込みSQLの例など、多くの改善を行っているところです。
試してみたい方は、demo.gethue.comからワンクリックでアクセスできます。
その先へ!
Romain