Hue は 10周年を迎えました! このシリーズのフォローアップ第2弾では、SQL Cloud エディタとは何かを説明します。
SQL Cloud エディタの上位2つの機能は次の通りです。
データのクエリ体験: SQL クエリアシスタントを提供します。これは、ユーザーのクエリに必要なセルフサービスを行い、データと構文のノウハウを学ぶのに役立ちます。クラウドネイティブ: サービスの操作を自動化することにより、可能な限り「何も操作しないこと(No-ops)」を提供することで、サービスをスケールします。これには、簡単な実行と監視、容量のオートスケール、自動的なローリングアップグレードなどが含まれます。
この投稿では、エンドユーザーの観点からクエリ体験を詳しく説明します。シリーズ第3弾ではクラウド体験に焦点を当てる予定です。
SQL データウェアハウスにフォーカス
多くのデータプラットフォームは、通常 データハブ モデルで構成されます。これは、全てのデータ、計算、およびワークフロースケジューリングやインデキシング、ストリーミングなどのサテライトサービスを全て備えた、中央型のクラスターを意味します。
これは、本格的な Hue を介してアクセスする多くのコンポーネントです。
Hueのアプリは、インデックス付きまたはSQLでデータの計算やチャートのためのダッシュボード 、AWS、Azure、Google Cloud のクラウドストレージ用のブラウザー、ジョブワークフロー用の ワークフロースケジューラー データセットインポートウィザード…など数多くあります。
しかし、SQLデータウェアハウスの場合、Hue を主にエディターとデータカタログに制限します。
このようにして、SQL 計算エンジンとデータストレージが簡単にクエリまたは閲覧できます。
SQL クエリ体験
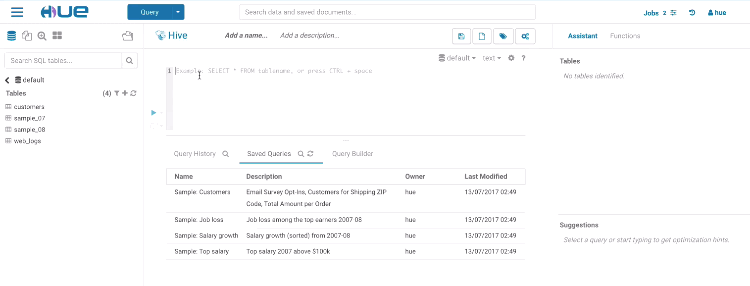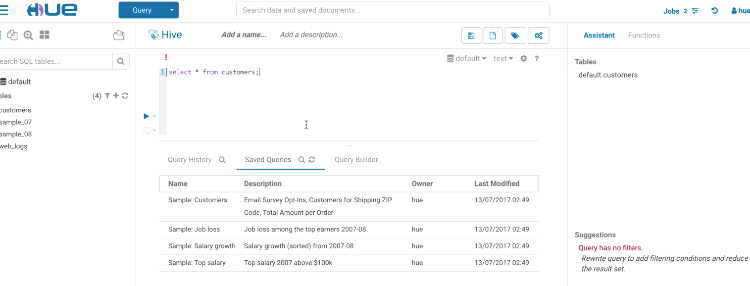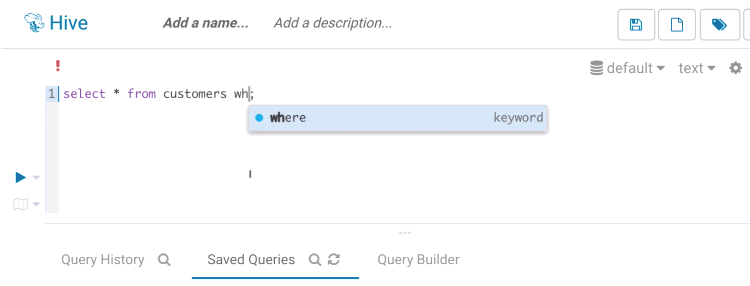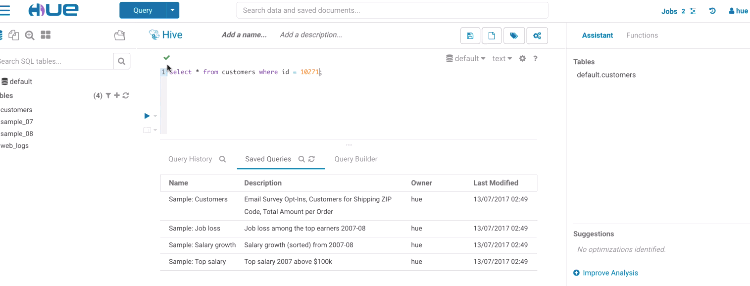
データのクエリは難解です。既存データセットの知識とそれらをクエリする方法は単純ではありません。従来の SQL エディタは、データアナリストのSQL開発者のような上級ユーザーとフルタイムのユーザーを対象とし、オプションで満たされているインターフェースを提供していました。
最近の傾向は、よりシンプルなインターフェースをより幅広いエンドユーザーに提供し、基本的にビッグデータエコシステムの複雑さを最大限に隠蔽することです。一般的に、フルタイムではないデータアナリストはどこから始めるのかさえ知らないため、スマートエディターは、データの説明とクエリする方法をクラウドソースする必要があります。
アドホッククエリも同様に、組織内の様々な専門職が基本的な質問への回答を要求する主要なユースケースです。例えば、
- 今週および先週のブログの投稿は何回クリックされましたか
- 製品 X の日本地域での売り上げはどのぐらいでしょうか
- 私のチームでの、Salesforceでの顧客のトップケースは何ですか…
そして、分析チームに新しいダッシュボードやSQLクエリを要求するのではなく、自身で答えることができればはるかに素早いです。多くの場合、セルフサービスを実現するのを妨げるのは次の理由です。
- データを見つける
- クエリを見つける
データを見つける
数千のデータベースで、暗号化された名前を持つ数千のうちの数十のテーブルでは、データを見つけることは簡単な作業ではありません。ユーザーは、クエリを入力して洞察を得る前に、正しいデータセットを見つけて探索する必要があります。
データブラウザとカタログはこの問題を解決するためにあり、Hue はこれらのサービスの統合を組み込みました。Apache Atlas は、テーブル、列の検索とコメントを強化しています。新しいカタログはコネクターを介して統合できます。
トップ検索
プロジェクトに関連するテーブル名を覚えるのに苦労したことはありませんか? これらの列やビューを見つけるのに時間がかかり過ぎていませんか? Hue を使用すると、クラスター内の全てのデータベースで任意のテーブル、ビュー、または列を簡単に検索できます。数万のテーブルを検索できるので、素早いデータディスカバリーの必要な、関連するテーブルを素早く見つけることができます。
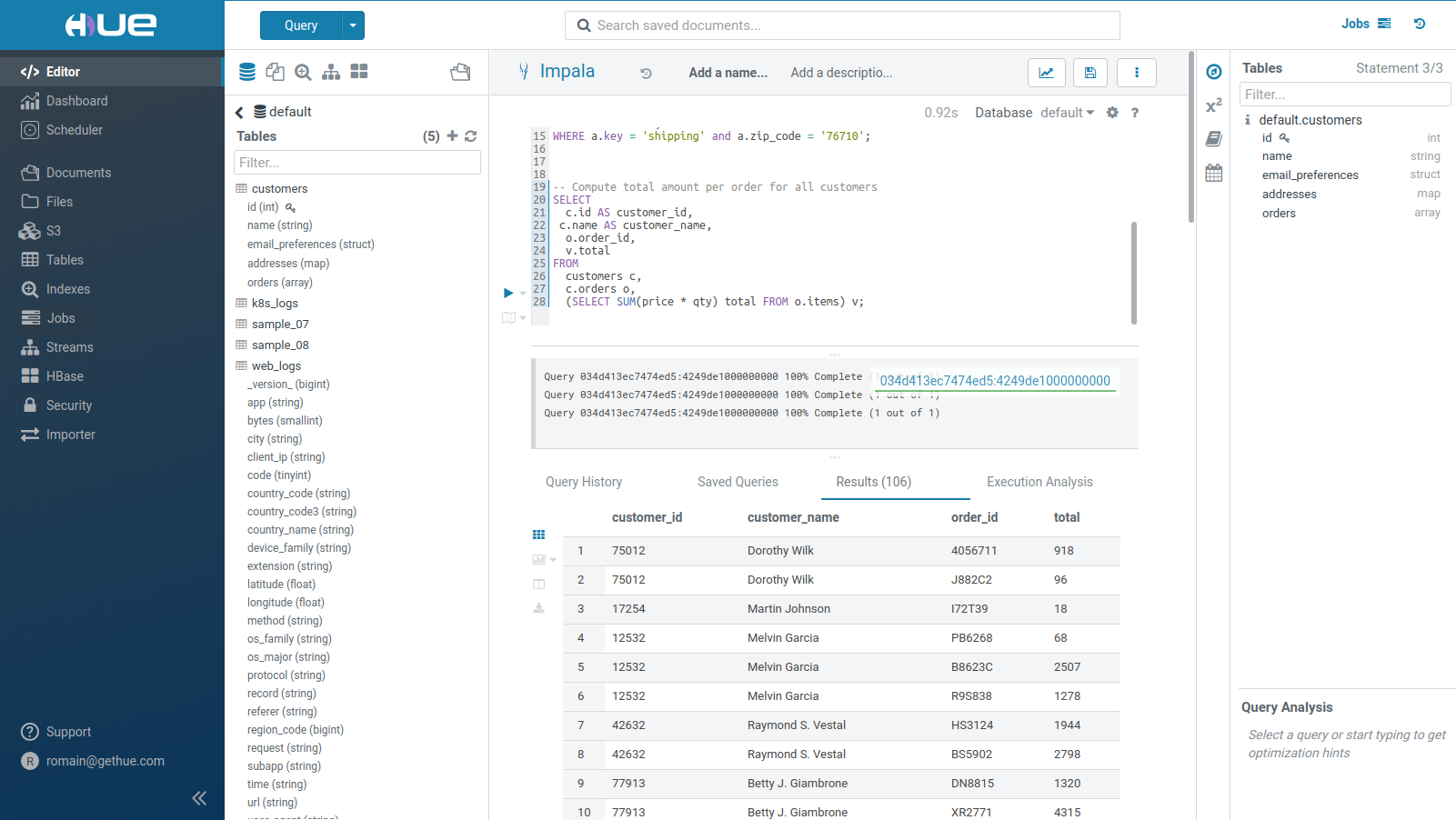
検索バーは常に画面上部からアクセスできます。Hue がメタデータサーバーにアクセスするように設定されている場合は、ドキュメント検索とメタデータ検索も提供します。
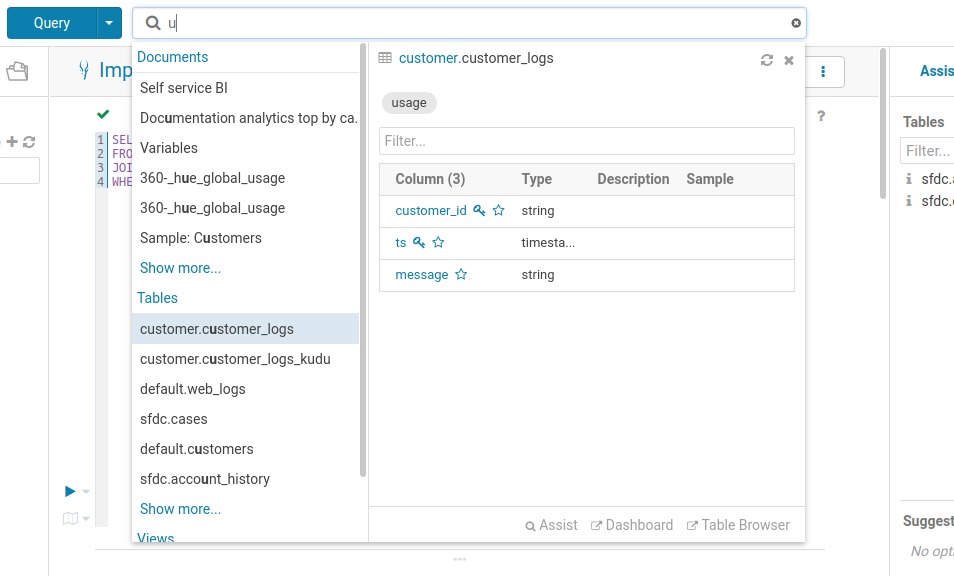
クラスターで利用可能なクエリまたはデータの検索
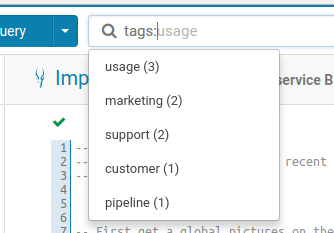
フィルタリング可能なタグの一覧
検索
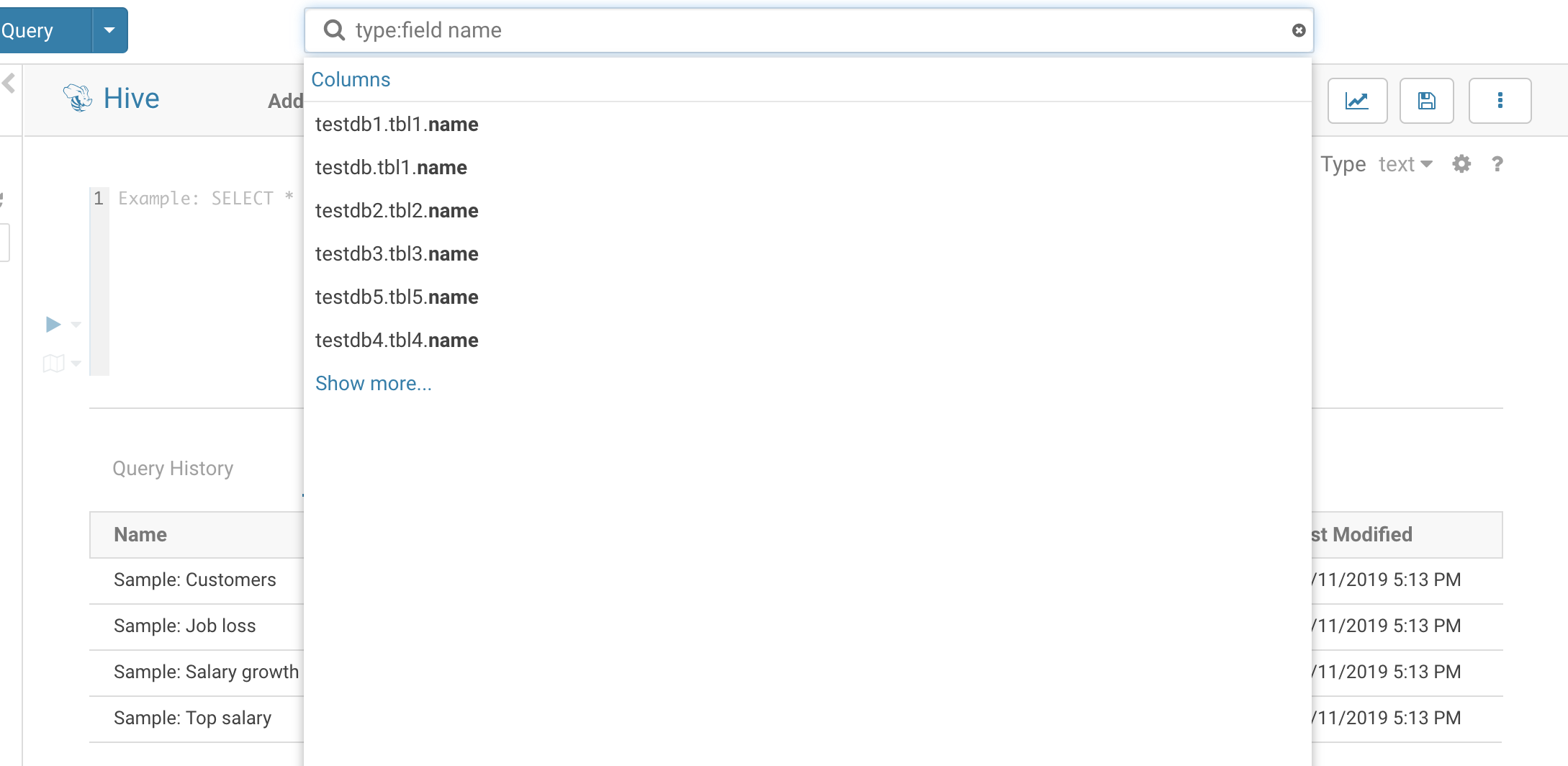
デフォルトでは、テーブルとビューのみが返却されます。列、パーティション、データベースを検索するには「type:」フィルターを使用します。
検索構文の例:
Apache Atlas
- sample → 「sample」接頭辞を持つテーブルまたは Hue のドキュメントが返却される
- type:database → このクラスターの全てのデータベースの一覧表示
- type:table → このクラスターの全てのテーブルの一覧表示
- type:field name→ フィールド(列)が 「name」を持つテーブルの一覧表示
- ‘tag:classification_testdb5‘ または ‘classification:classification_testdb5’→ 分類 「classification_testdb5」のエンティティーの一覧表示
- owner:admin→ 「admin」ユーザーが所有する全てのテーブルの一覧表示
Cloudera Navigator
- table:customer → customer テーブルを見つける
- table:tax* tags:finance → tax で始まり「finance」でタグづけられた全てのテーブルを一覧表示
- owner:admin type:field usage → usage 文字列に一致する、admin ユーザーによって作成された全てのフィールドを一覧表示
- parentPath:"/default/web_logs” type:FIELD originalName:b* →
defaultデータベースのweb_logsテーブルのbで始まる全ての列を一覧表示
追加メタデータ
Hue のバージョン1から利用可能だった、テーブル、ビュー、列など任意のSQLオブジェクトのタグの編集に加えて、テーブルの説明も編集できるようになりました。これにより、エンドユーザーはメタデータのセルフサービスドキュメント化が可能です。
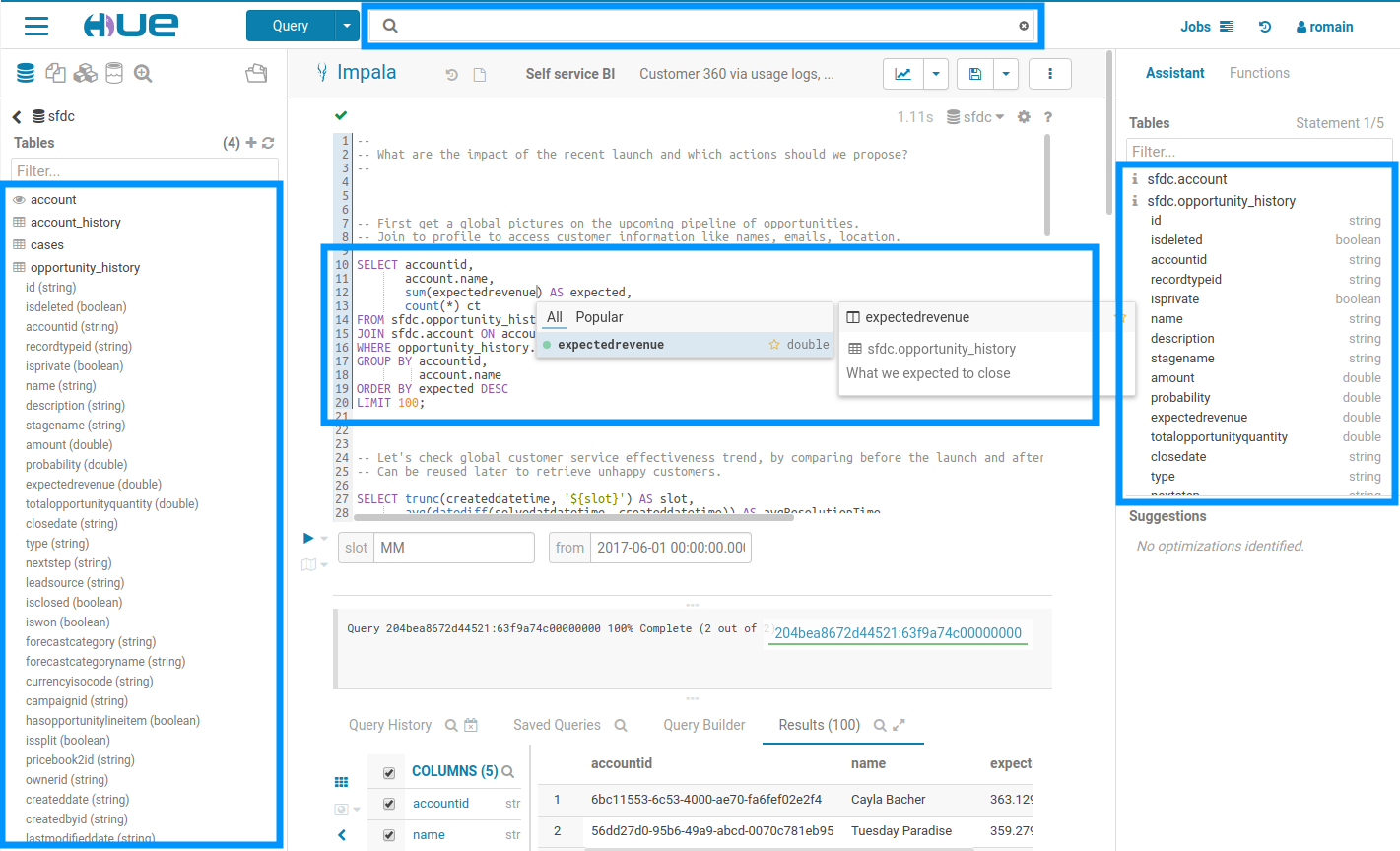
左側パネルでのアシスト
必要な時に必要な場所にあるデータ
ページを離れることなく、クエリ、テーブルおよびファイルを見つけることができます。アイテムを右クリックするとアクションの一覧が表示されます。ファイルをドラッグ&ドロップして、エディターでパスを取得することなどもできます。
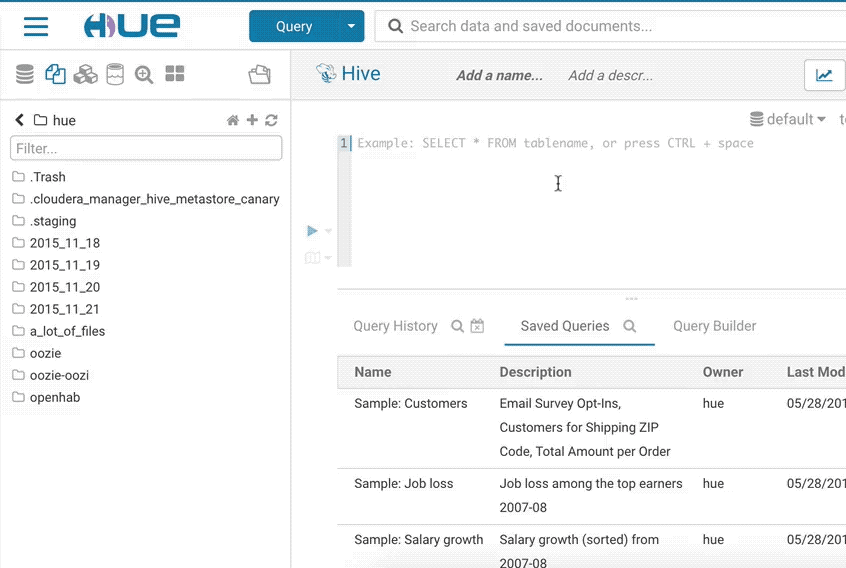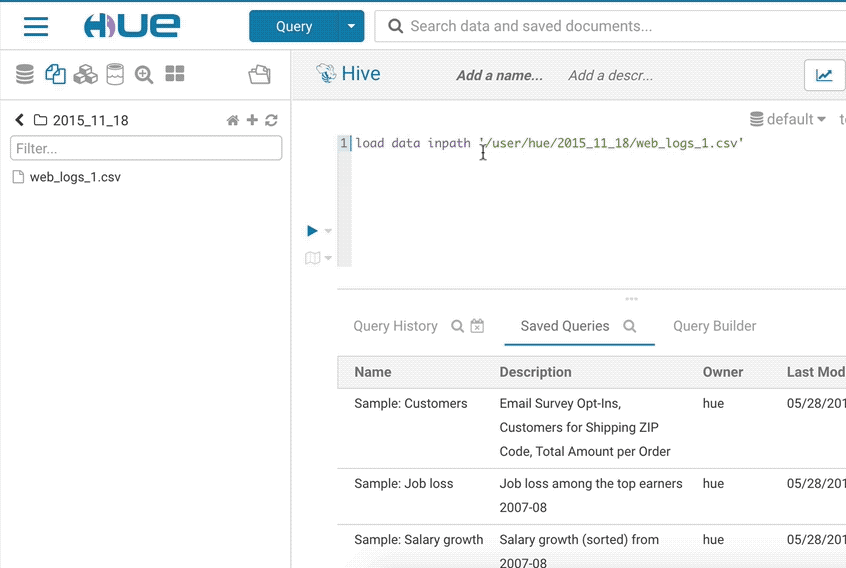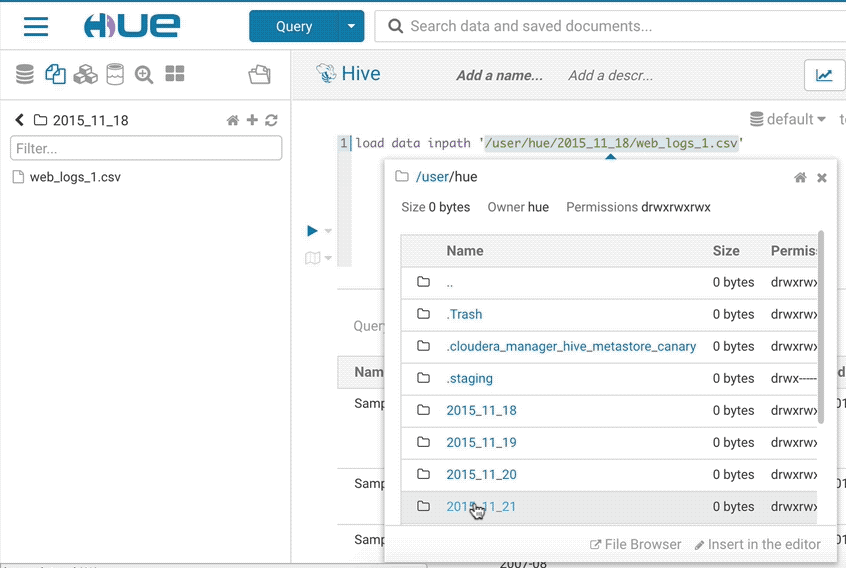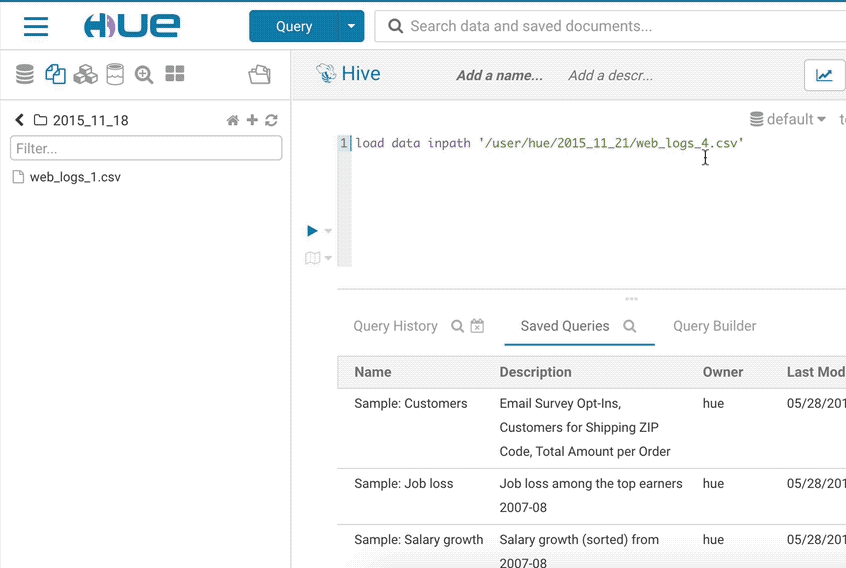
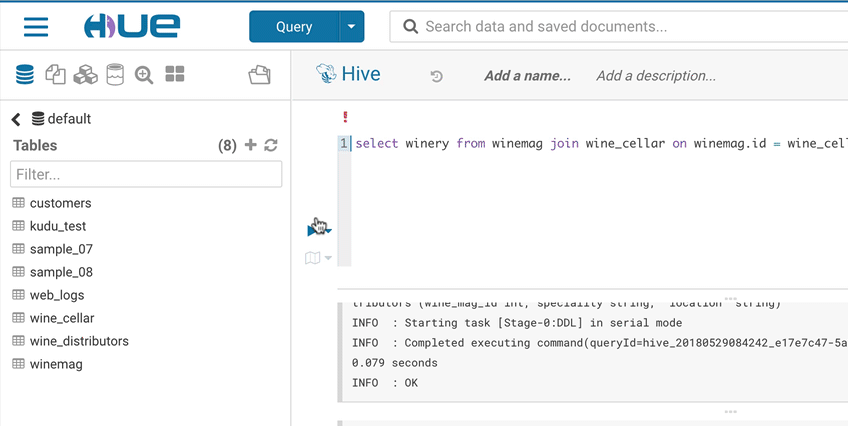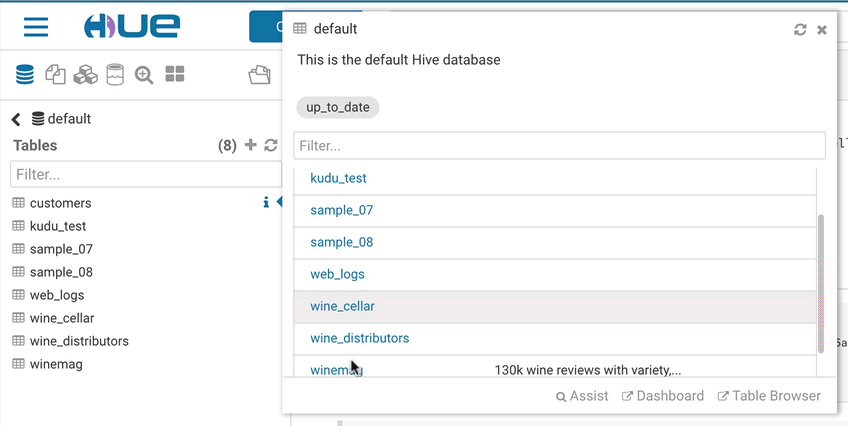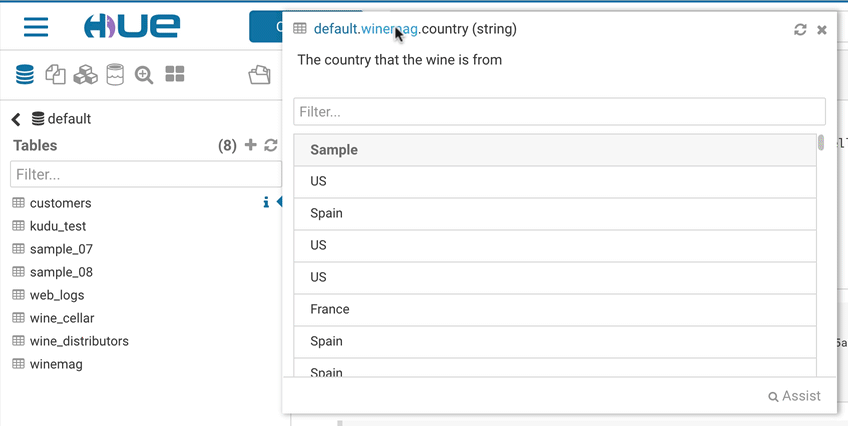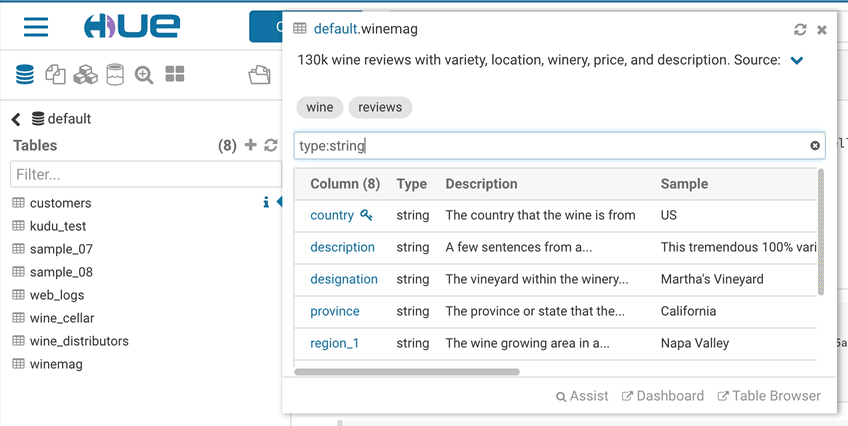
サンプルポップアップ
このポップアップは、データベース、テーブル、および列に関するデータのサンプルやその他の統計情報を素早く表示する方法を提供します。SQLアシストまたは任意のSQLオブジェクト(テーブル、列、関数..)を右クリックして、ポップアップを開くことができます。このリリースでは、より素早く開くようにもなり、データもキャッシュします。
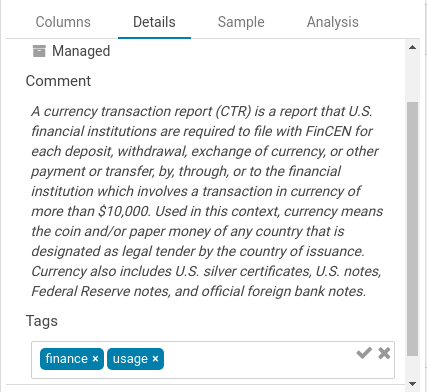
タグ付け
さらに、オブジェクトに名前をタグ付けしてより適切に分類し、異なるプロジェクトにグループ化もできます。これらのタグは検索可能であり、より簡単でより直感的な発見を通じて探索プロセスを促進します。
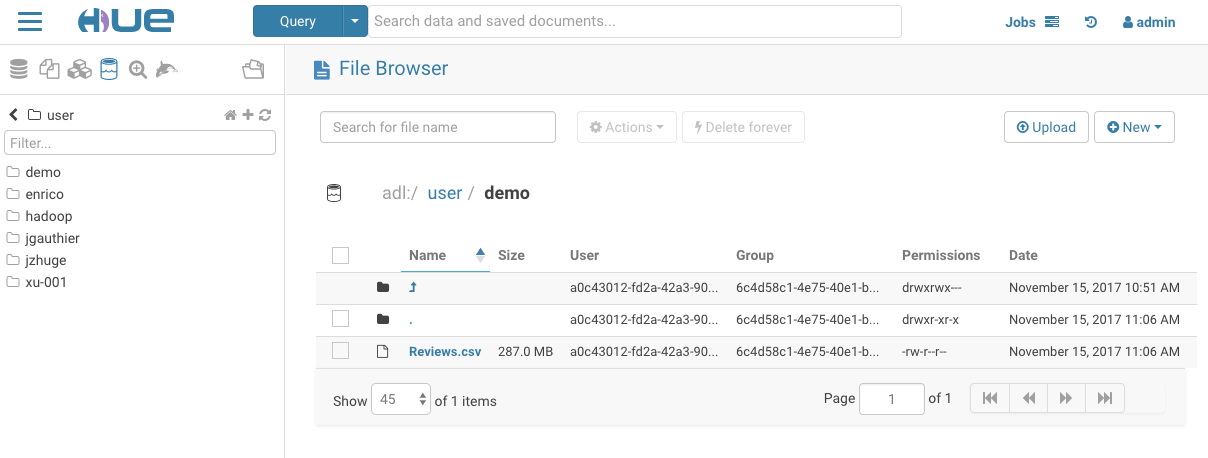
データの閲覧
ファイルブラウザーアプリケーションを使用すると、HDFS, AWS S3, Azure ADLS v1 および v2 (ABFS)のファイルシステムとやり取りができます。Google Cloud Storage は現在対応中です。HUE-8978.
ストレージのルート(一番上)をクリックして、アカウント内のアクセス可能な全てのフォルダを表示します。ここからディレクトリとファイルの作成、既存のディレクトリとファイルのリネーム、移動、コピー、削除を行います。さらに、ファイルをストレージに直接アップロードします。
データのインポート
インポーター (Importer) の目標は、まだクラスターにはないデータに対するアドホックなクエリを許可し、セルフサービスの分析をシンプルにすることです。
独自のデータをインポートしたり、テーブルにない既存のデータを参照したい場合は、左側のメニューまたは左側のアシストの小さな + からインポーターを開きます。インポートウィザードでは、ストレージ内のファイルから外部 Hive テーブルを直接作成できます。
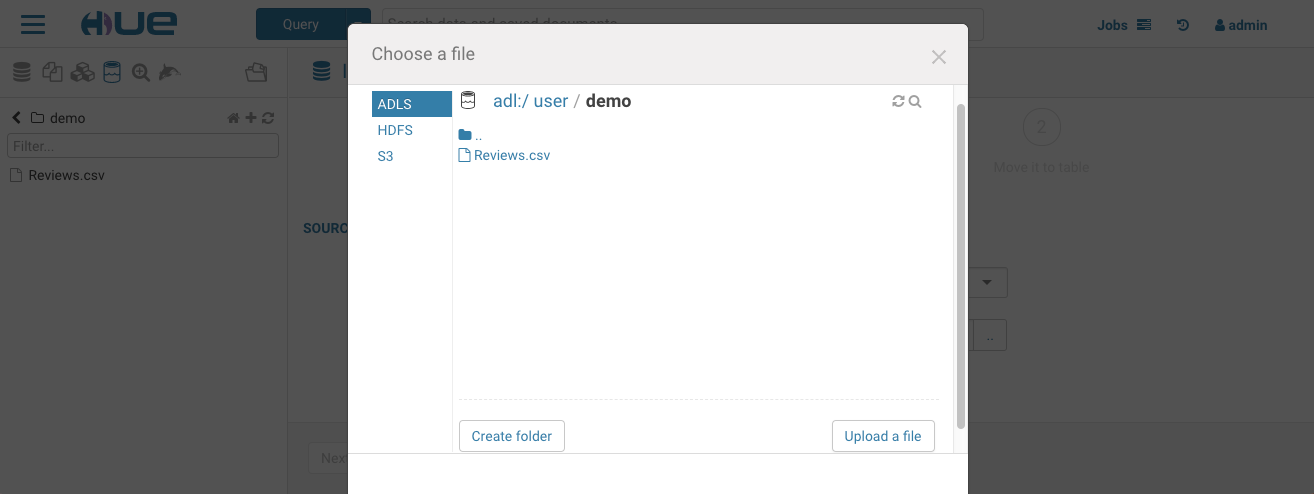
データのクエリ
テーブルが見つかったら、クエリを実行して質問に答えたり洞察を発見します。
クエリの実行
SQL クエリの実行は、エディターの主なユースケースです。最も一般的なデータベースとデータウェアハウス の一覧をご参照ください。
- 現在選択されているステートメントには、左側に青色の境界線があります。クエリの一部を実行するには、1つ以上のクエリのステートメントをハイライトします。
- 実行します。その後クエリの結果画面が表示されます。列のスクロール、列の名前の種類のフィルタリング、プロット、行の固定と展開、セルの内容の検索などの操作を実行します。
- クエリに複数のステートメントがある場合 (セミコロンで区切られている場合)、複数ステートメントのクエリ画面で「Next」をクリックして残りのクエリを実行します。
複数のステートメントがある場合、実行したいステートメントにカーソルを置くだけで十分です。アクティブなステートメントは青色のガター(溝)のマークで示されます。
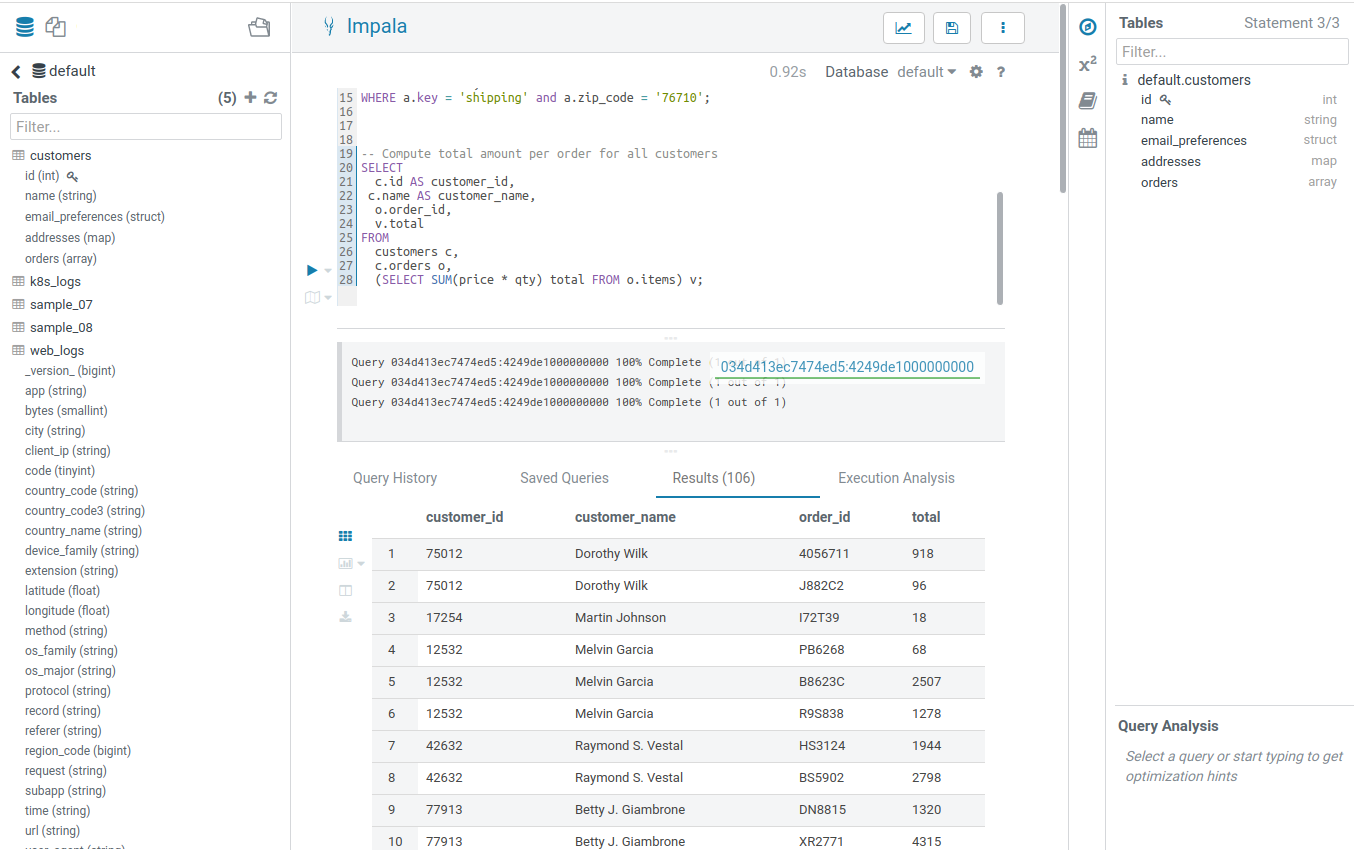
注: CTRL/Cmd + ENTER を使用してクエリを実行します。
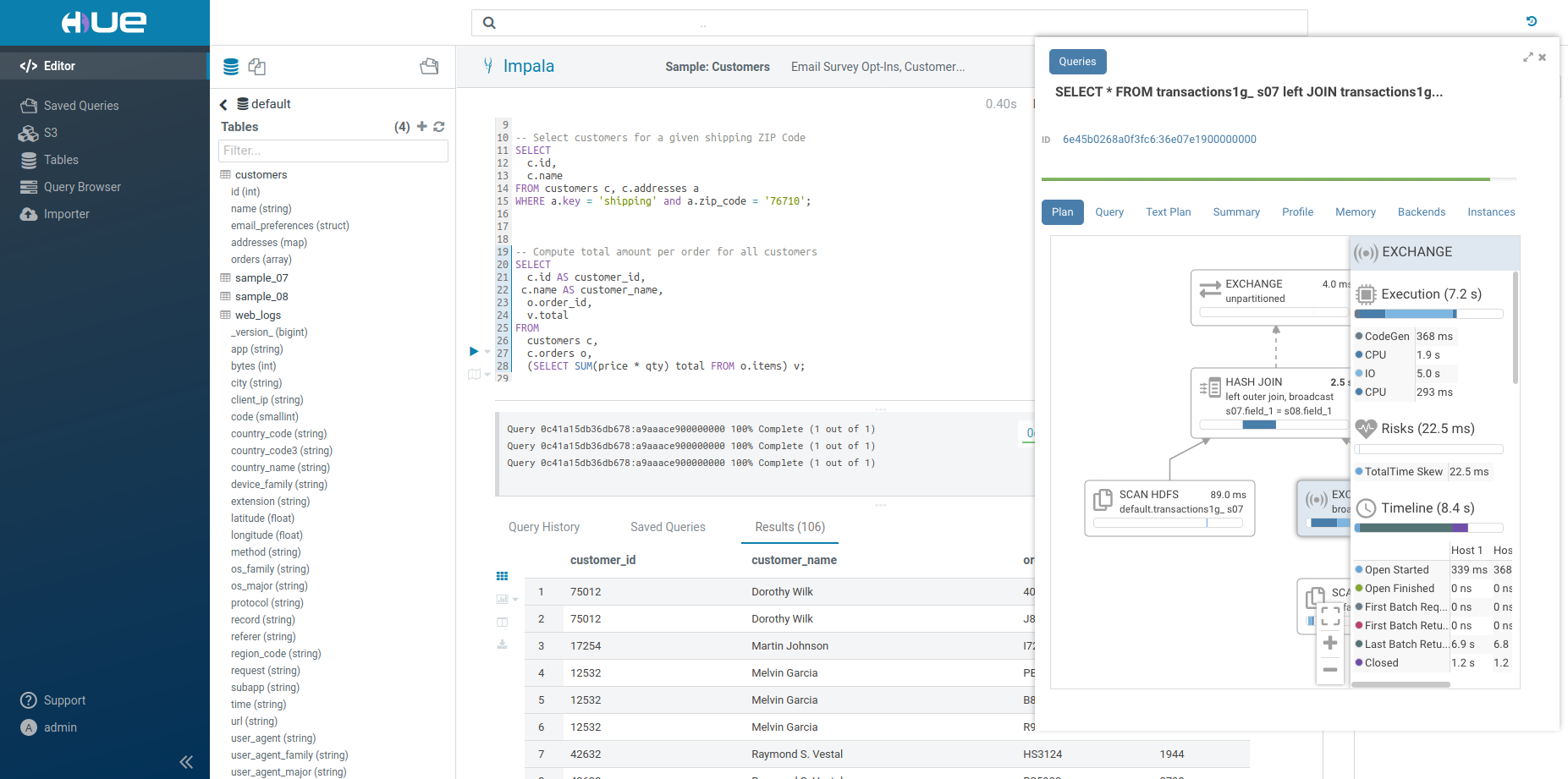
注: ログのパネルの上部には、クエリブラウザー でクエリのプロファイルを開くためのリンクがあります。
自動補完
自動補完は Hue が最高の輝きを放つ場所であり、Hue には地球上でトップクラスの SQL 自動補完が付属しています。オートコンプリーターは Hive および Impala の SQL 方言の全てを知っており、ステートメントの構造とカーソルの位置により、キーワード、関数、列、テーブル、データベースなどを提案します。
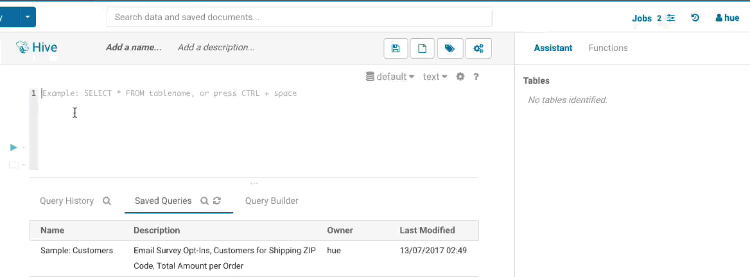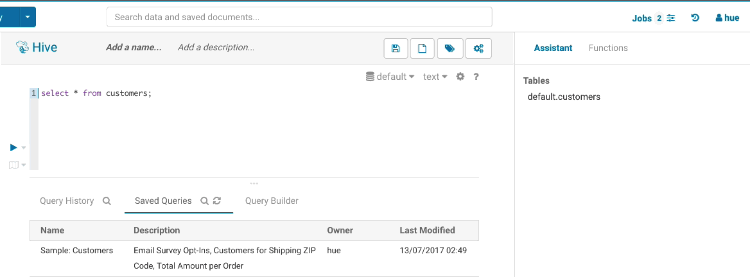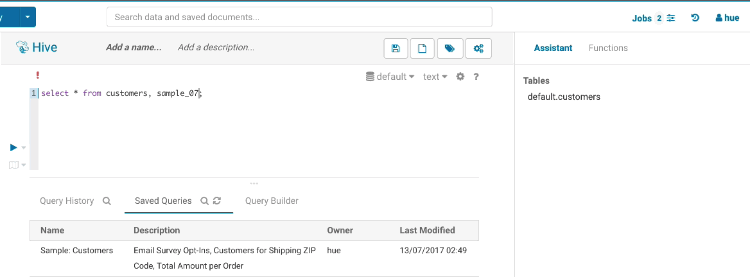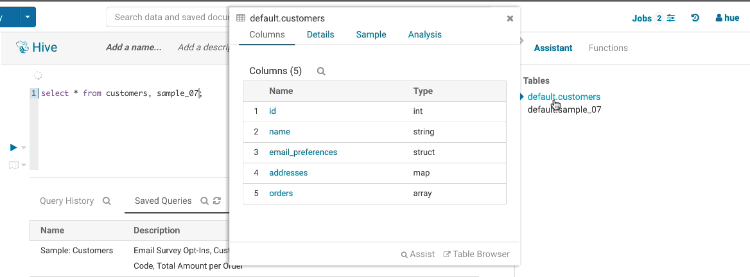
スマートな列の提案
FROM句に複数のテーブル(派生テーブルや結合済みのテーブル)が含まれている場合、全てのテーブルの列はマージされ、必要に応じて適切なプレフィックスが追加されます。また、エイリアス、ラテラルビュー、複雑な型についても認識しており、それらも含まれます。必要な場合、間違いを防ぐために予約語や風変わりな列名をバッククォートします。
スマートなキーワードの補完
オートコンプリーターは、ステートメント内のカーソルの位置に基づいてキーワードを提案します。可能であれば、IF NOT EXISTS のように一度に複数の単語を提案することもあります。誰もたくさん入力したくないでしょう?
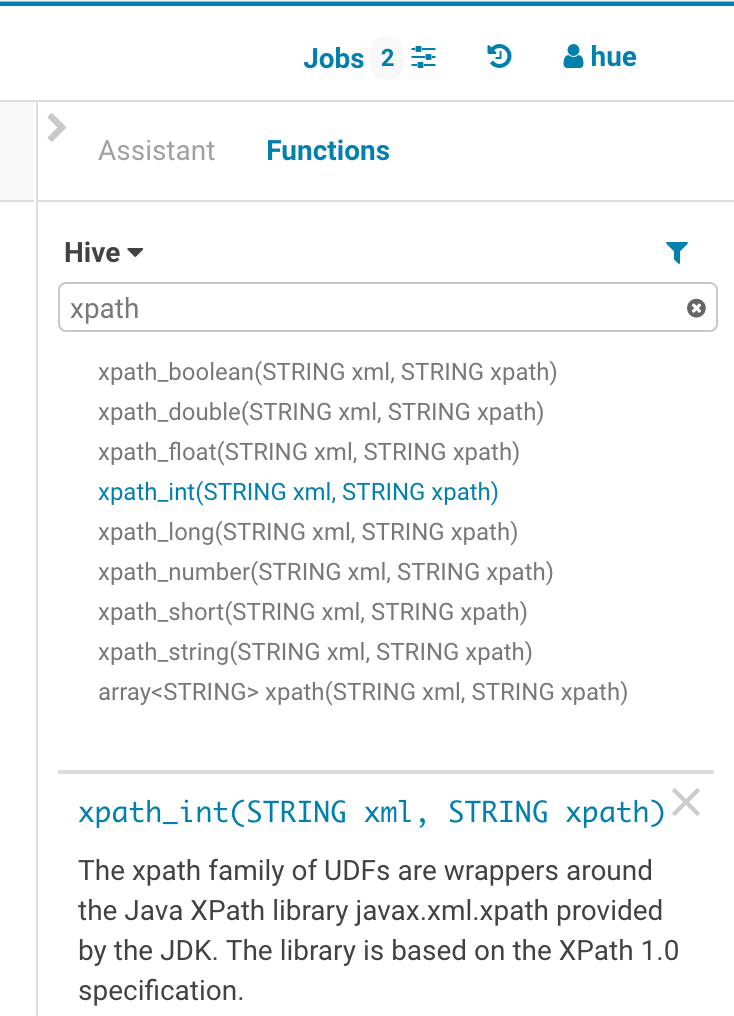
関数
改良されたオートコンプリーターは関数を提案します。各関数の提案の追加パネルが自動補完ドロップダウンに加わり、ドキュメントと関数の使用法を表示します。おートコンプリーターは引数に期待される型を認識しており、引数リスト内のカーソルの場所で引数に一致する列または関数のみを提案します。
サブクエリ、相関の有無
サブクエリを編集する場合、サブクエリの範囲内でのみ提案を行います。相関サブクエリの場合、外部テーブルも考慮されます。
コンテキストのポップアップ
クエリのフラグメント(テーブル名など)を右クリックして、全てのメタデータ情報を取得します。これは、詳細説明を取得したり、テーブルや列に含まれる値の型を確認するための便利なショートカットです。
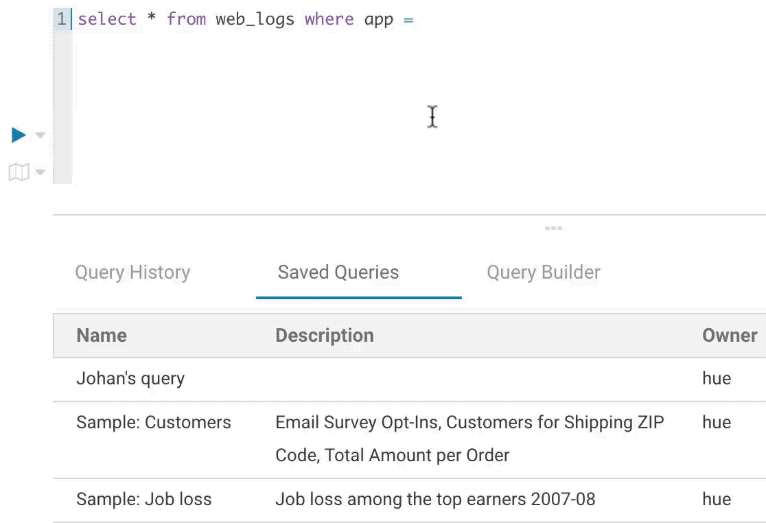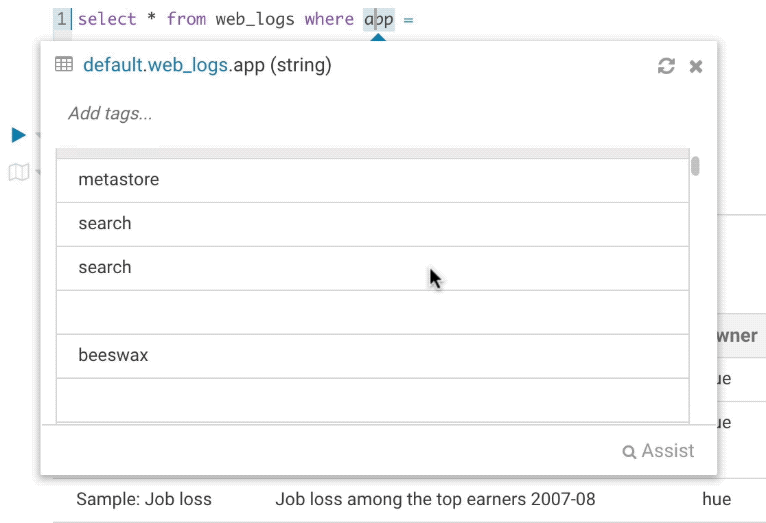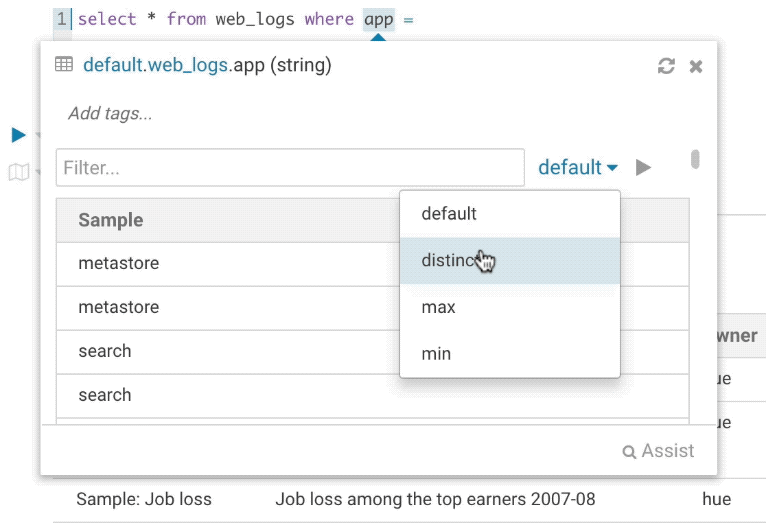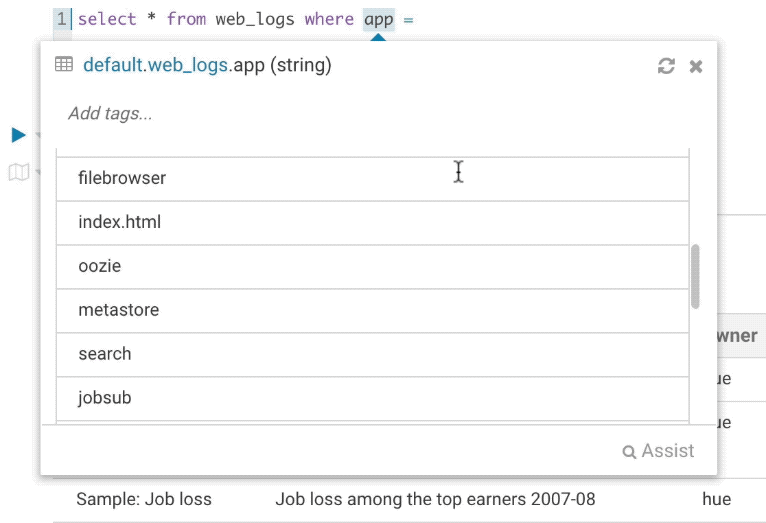
クエリの記述中に列のサンプルを見て、期待する値の型を確認できるとかなり便利です。Hueはサンプルデータに対していくつかの操作を行えるようになり、distinctした値と最小値、最大値を表示できるようになりました。
構文チェッカー
小さな赤い下線で誤った構文を表示することで、投入する前にクエリを修正することができます。右クリックすると提案が表示されます。
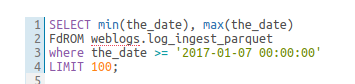
構文チェッカーのハイライト
構文チェカーの修正の提案
テーブルのアシスト
データウェアハウスエコシステムは、トランザクションの導入によりさらに完全になっています。実際には、これはテーブルが、パーティションキー同様に、主キー, INSERT, DELETE および UPDATE をサポートしたということです。
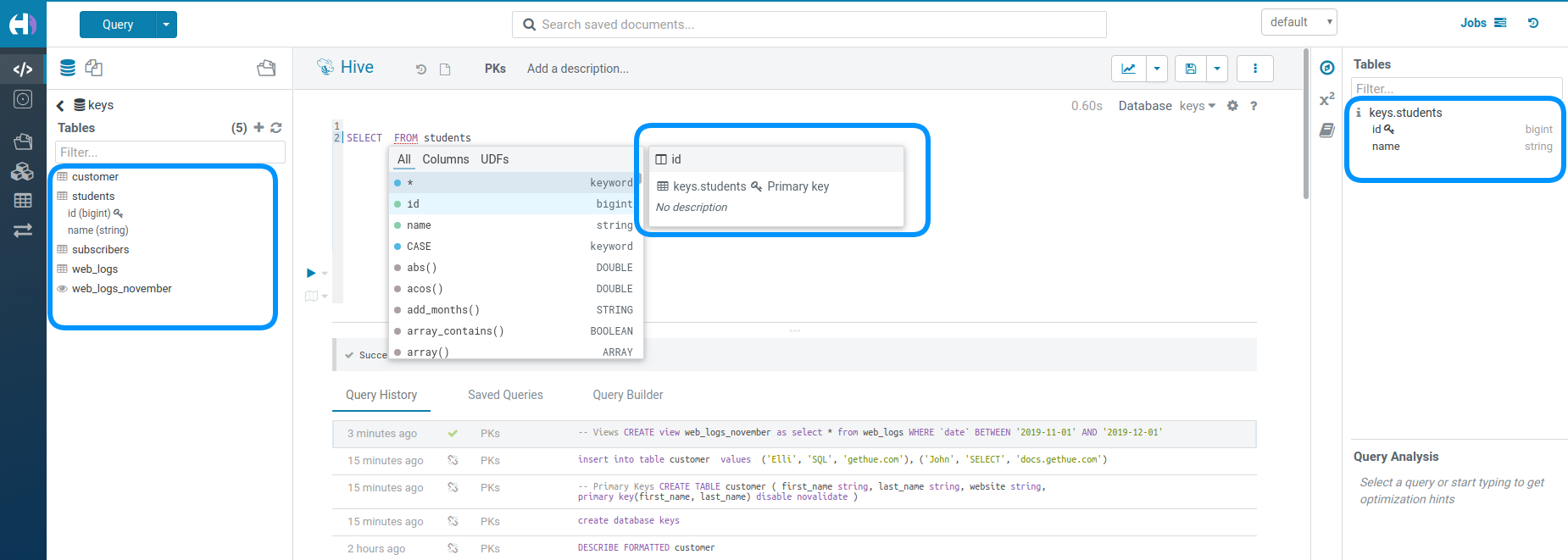
主キーは、鍵のアイコンがついたパーティションキーのように表示されます。
データのパーティショニングは、クエリを最適化するための重要な概念です。これらの特別な列にも鍵のアイコンが表示されます。

複合型、またはネスト型は、関連するデータを近くに保存するのに便利です。アシストを使用して列のツリーを展開できます。

テーブルの代わりにビューであることを意識しないと混乱する場合があります。ビューは小さな目のアイコンで表示されます。
![]()
言語リファレンス
言語リファレンスマニュアルは右側のアシストパネルにあります。これは選択されたSQLエンジンとクエリに依存します。現在のテーブル、言語、UDFのドキュメントが表示されます。
この初期バージョンでは、上部のフィルターの入力はトピックのタイトルのみをフィルターします。以下は、SELECT ステートメントの結合に関するドキュメントを探す方法の例です。
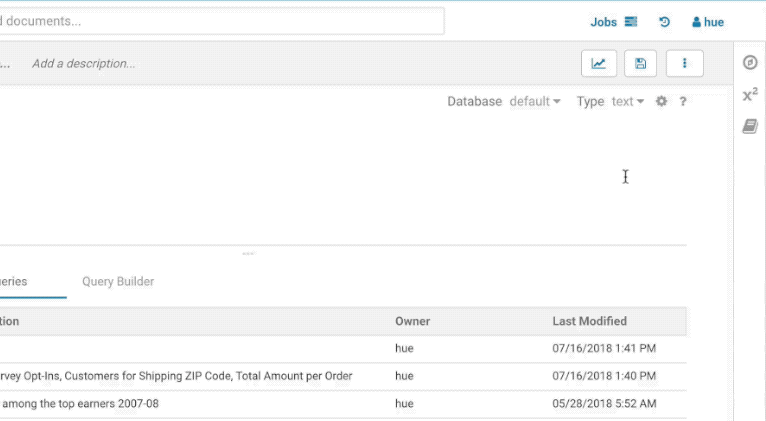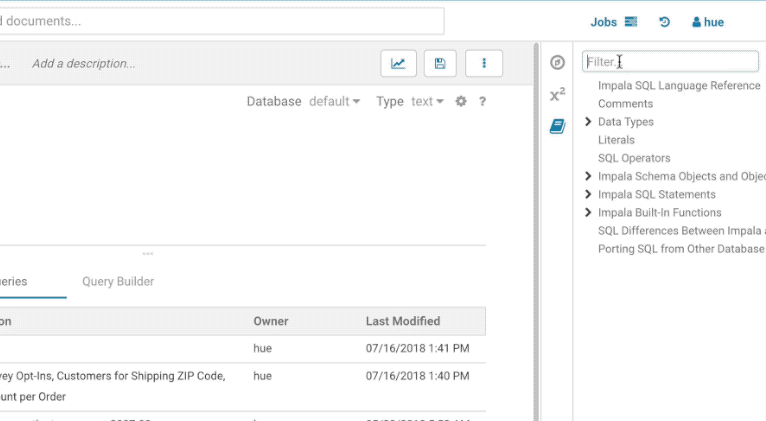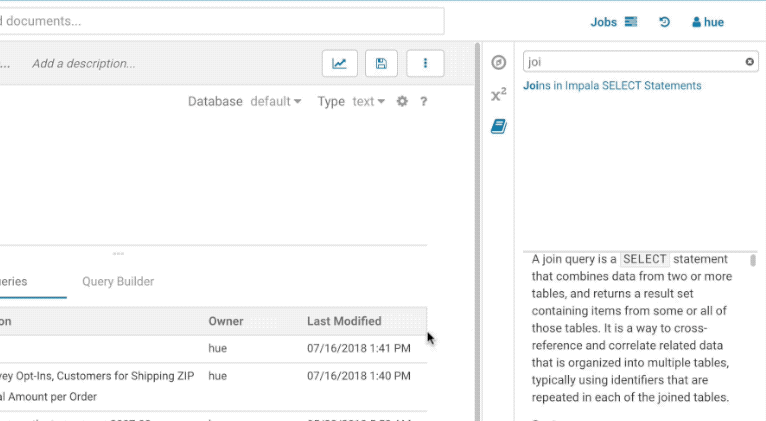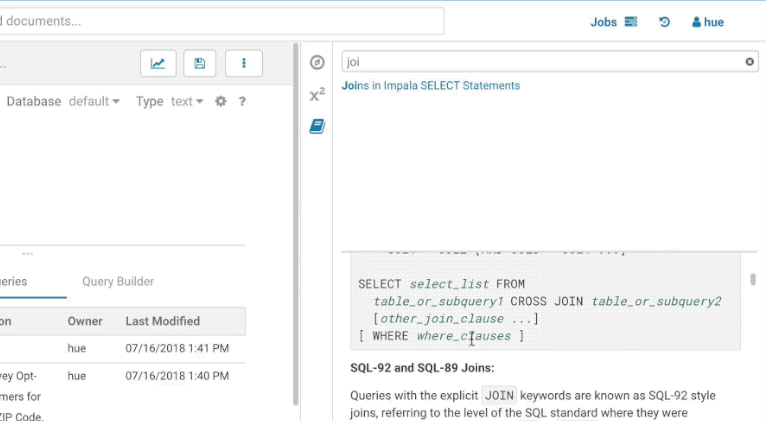
ステートメントの編集中、現在のステートメントの型の言語リファレンスを素早く見つけるための方法があります。最初の単語を右クリックすると、下のポップアップにリファレンスが表示されます。
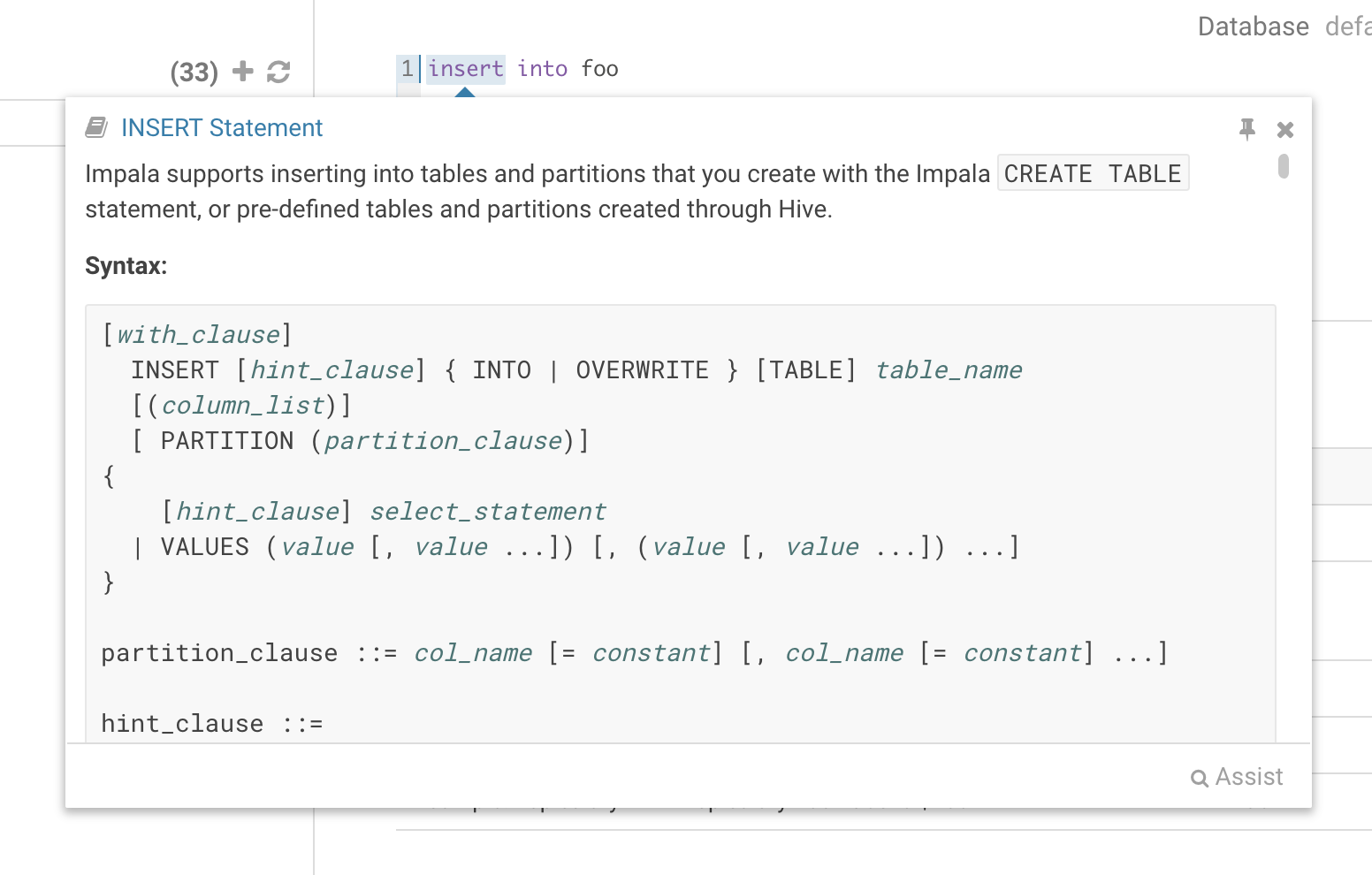
変数
変数は、クエリ内のパラメーターを簡単に設定するために使用されます。これらは共有、あるいは繰り返し実行可能なレポートを保存するのに最適です。
単一の値
SELECT * FROM web_logs WHERE country_code = "${country_code}"
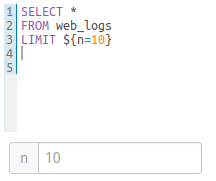
変数にデフォルト値の設定が可能
SELECT * FROM web_logs WHERE country_code = "${country_code=US}"
複数の値
SELECT * FROM web_logs WHERE country_code = "${country_code=CA, FR, US}"
複数の値の変数の表示テキストも変更可能
SELECT * FROM web_logs WHERE country_code = "${country_code=CA(Canada), FR(France), US(United States)}"
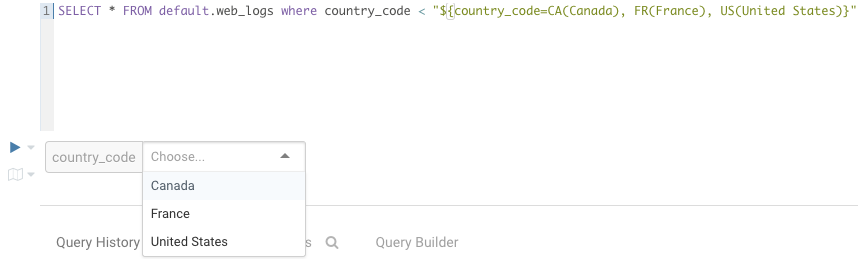
テキストではない値は引用符を省略
SELECT * FROM boolean_table WHERE boolean_column = ${boolean_column}
チャートの作成
これらの可視化は、時系列データをプロットする場合あるいは行のサブセットに同じ属性が含まれる場合に便利です。それらは一緒に積み重ねて表示されます。
- 円グラフ
- ピボット付きの棒グラフ、線グラフ
- タイムライン
- 散布図
- 地図 (マーカーとグラデーション)
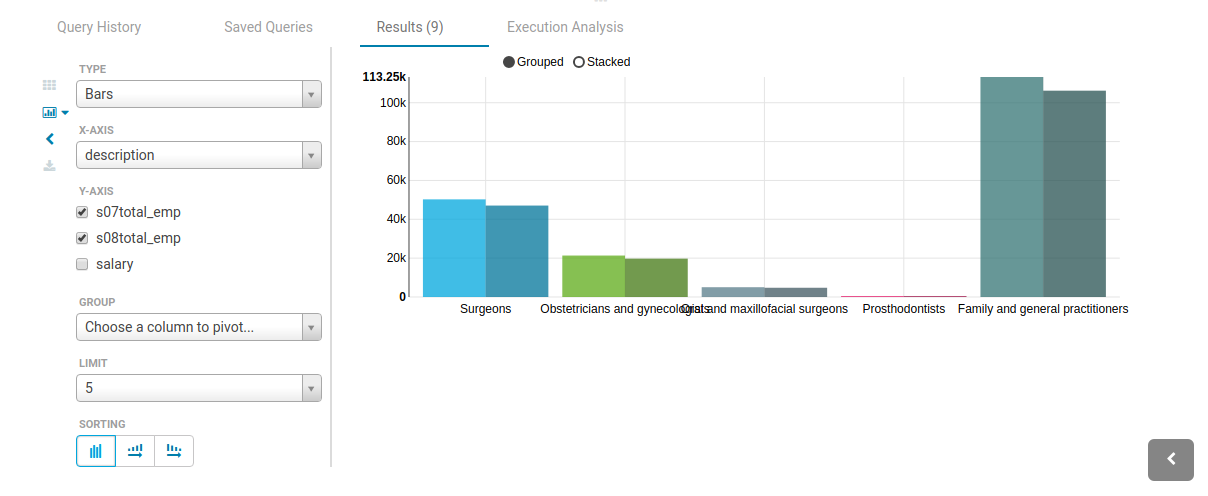
モード
プレゼンテーション
「ダッシュボード」アイコンをクリックして、セミコロンで区切られたクエリのリストを対話的なプレゼンテーションへと変換します。これは、シナリオを用いてプレゼンテーションを行い、ライブの結果でポイントを証明したり、ワンクリックで一連のクエリを含んだレポートを実行するのに便利です。
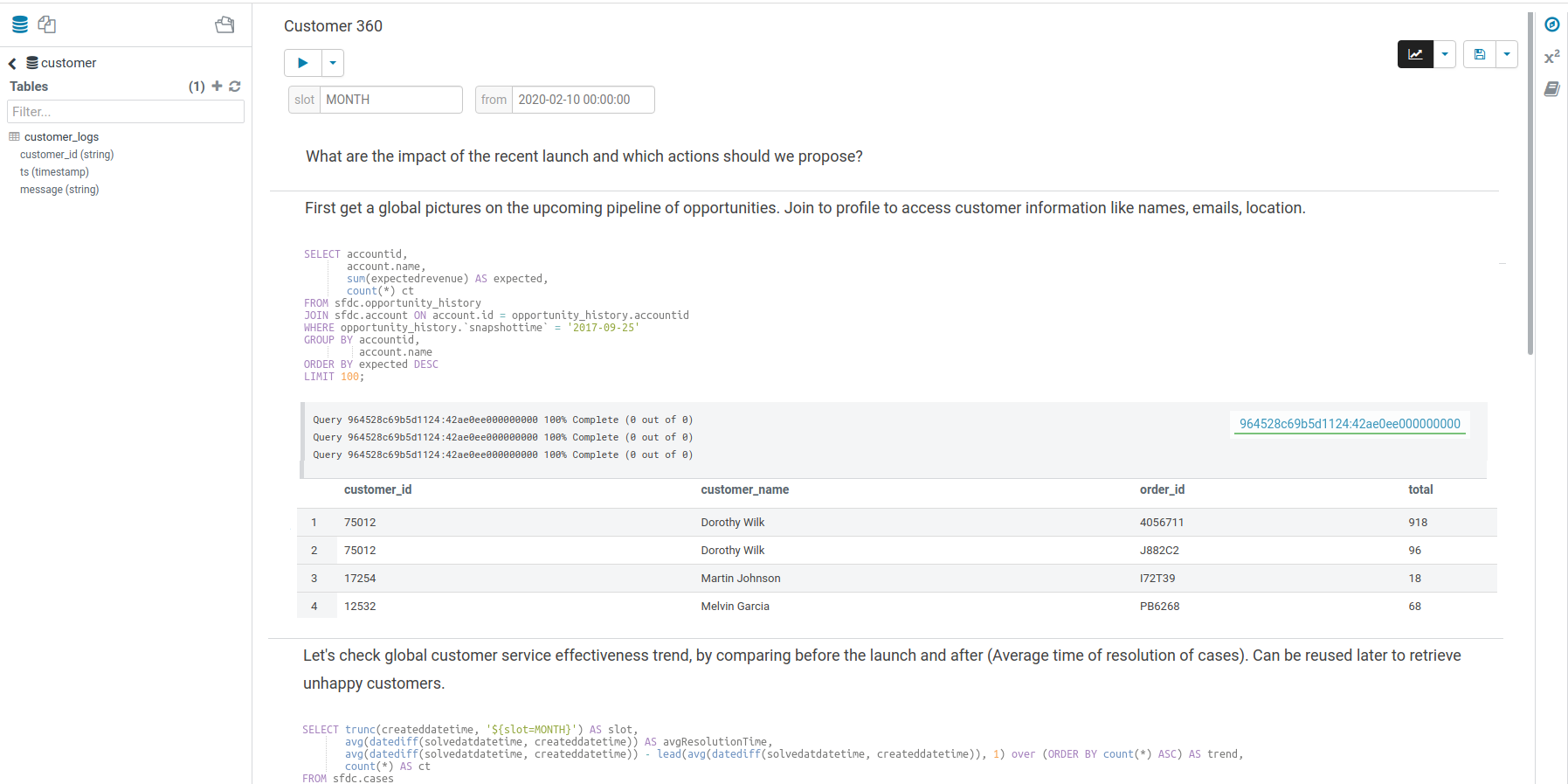
ダークモード
ダークモードは、初期バージョンでは Hue 全体をカバーするように拡張するのではなく、エディターの領域に制限されています。
ダークモードを切り替えるには、エディターに焦点があっているときに Ctrl-Alt-T、Mac では Command-Option-T を押すことができます。代わりに、Ctrl-、Mac では Command- を押して表示される設定メニューから制御できます。
クエリのトラブルシューティング
クエリの実行前
ポピュラーな値
オートコンプリーターは、Navigator Optimizer からのメタデータに基づいて、ポピュラーなテーブル、列、フィルター、結合、グループ化、ソートなどを提案します。オートコンプリーターの結果ドロップダウンに新しい「Popular」タブが追加され、ポピュラーな提案が利用できる際に表示されます。
これは、未知のデータセットで結合を実行したり、数百ものテーブルから最も興味深い列を取得したりする場合に特に便利です。
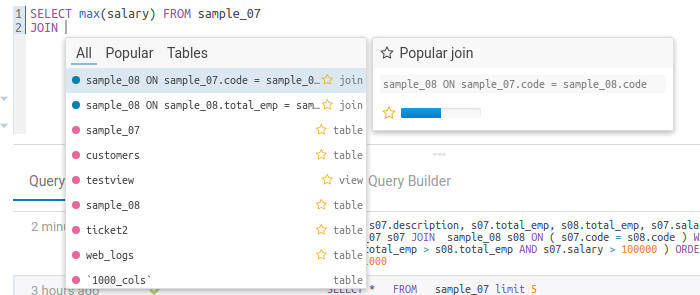
ポピュラーな結合の提案
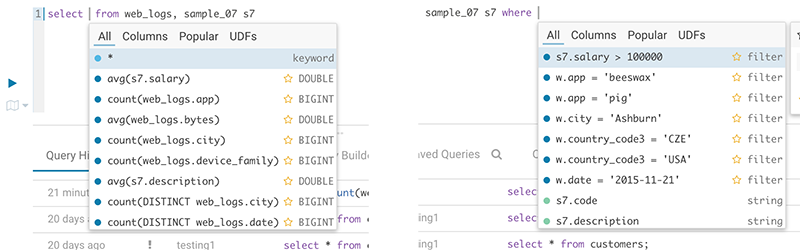
ポピュラーな列とフィルターの提案
リスクアラート
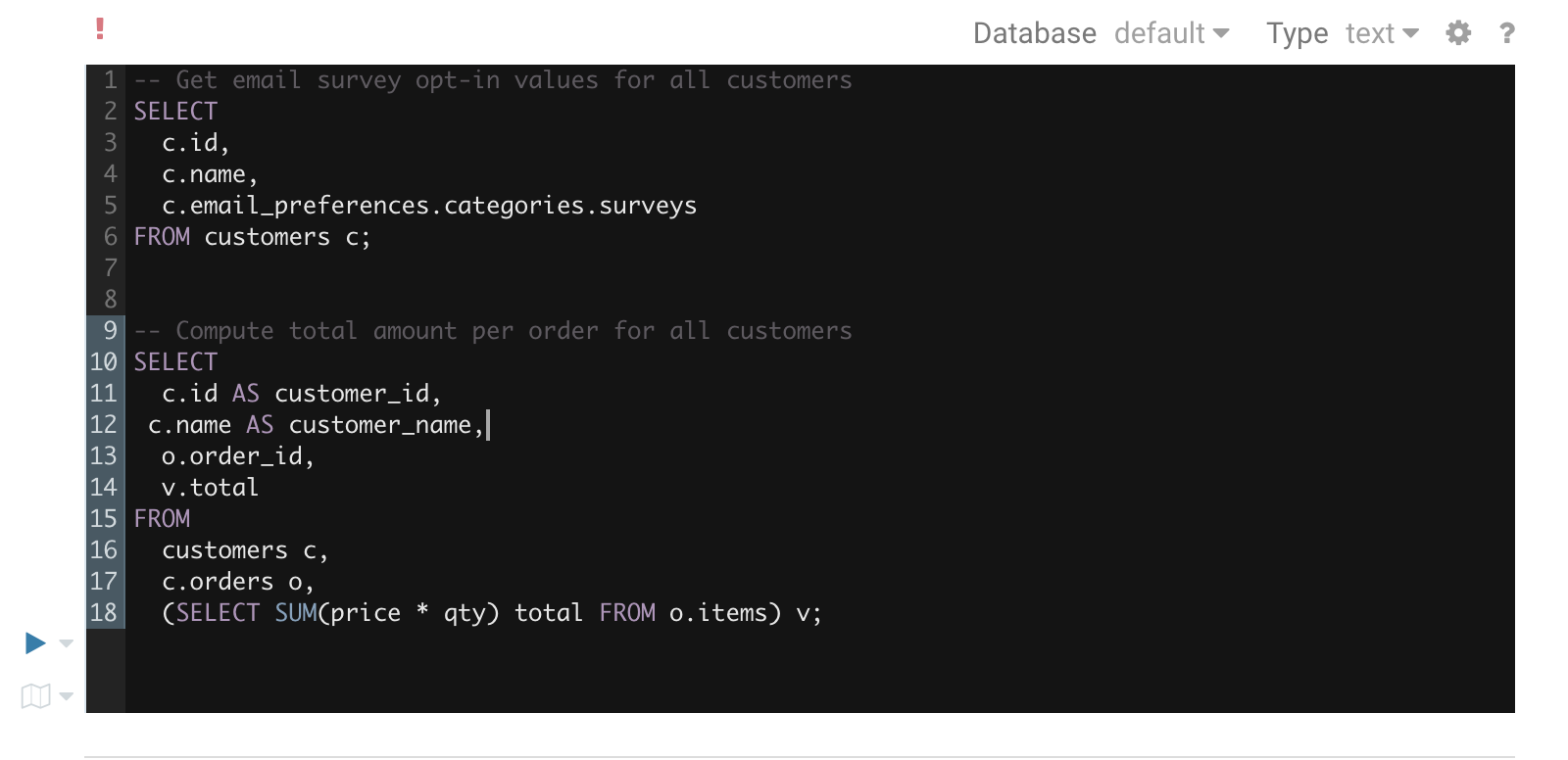
クエリの編集中、Hue はバックグラウンドで Navigator Optimizer を使用してクエリを実行し、クエリのパフォーマンスに影響する可能性のある潜在的なリスクを認識します。リスクと認識されるとクエリエディターの上に感嘆符が表示され、右側のアシスタントパネルの下部に、その改善方法に関する提案が表示されます。
クエリの実行中
Query Browser は、クエリの実行計画とボトルネックを表示します。検出されると「健全性」のリスクが修正方法の提案とともに一覧表示されます。
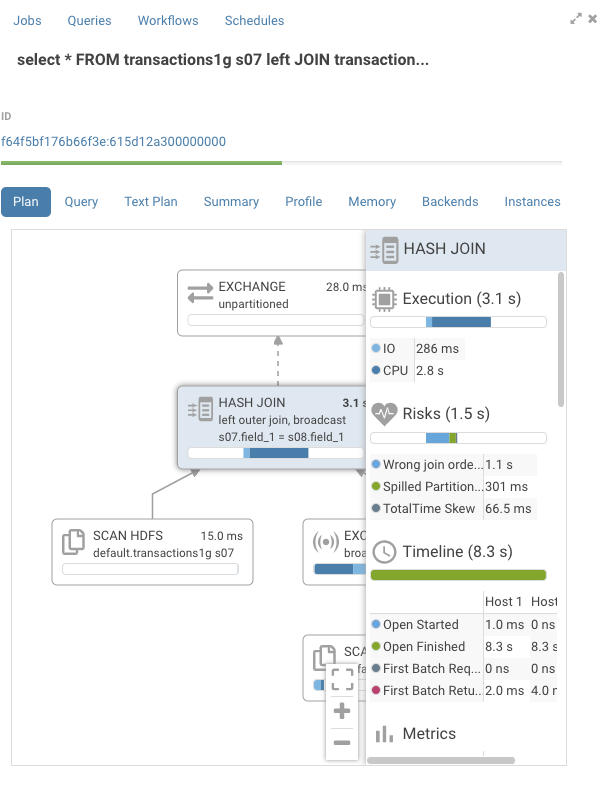
トラブルシュートの詳細 のシナリオのドキュメントがご利用いただけます。(英語)
共有
Google Document と同様に、クエリは他のユーザーやグループと、読み取り専用や編集権限とともに共有できます。共有はメインページまたは選択したアプリケーションの右上のメニューを介して行います。共有ドキュメントは小さな青いアイコンで表示されます。
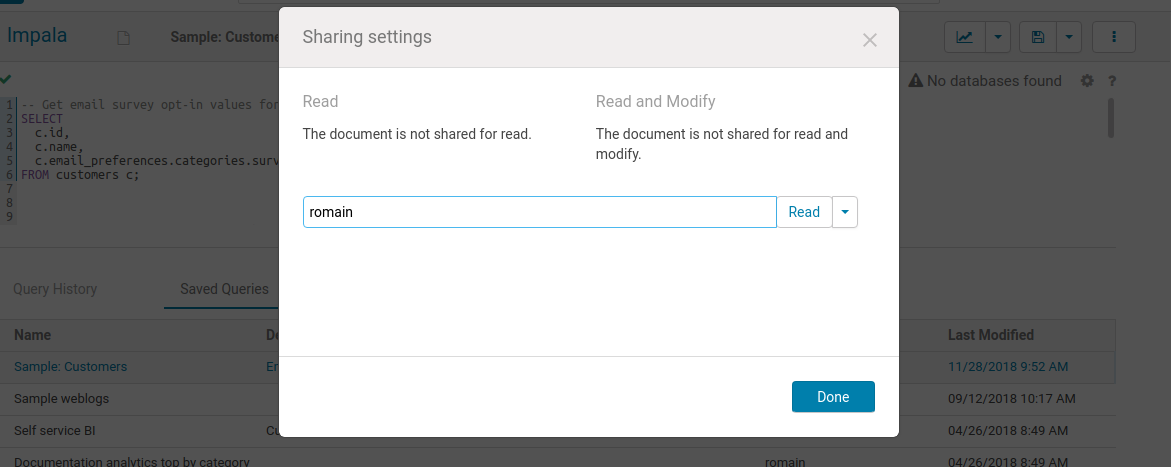
注: 一般向けのリンクと Gist での共有は、次の Hue 4.7 でリリースされる予定です!
次のステップ (SQL)
2020 年に Hue 5 および拡張された SQL Cloud エディタが登場し、より新しいデータクエリ体験が実現します。Cloudera Cloud Data Warehouse では、データウェアハウス専用の Hue もリリースされました。
Hue は、最もポピュラーなデータベースとそれら専用のSQL autocomplete に多くの connectors を使用して、さらにプラガブルになっています。
Hue の10年に渡る進化を紹介しているこのシリーズの第3弾では、SQL Cloud エディタの機能についてさらに深く取り上げます。それまでは、この記事やForum にコメントをお願いします。また、quick start で SQL のクエリを行なって下さい!
Romain, from the Hue Team