Hueでビッグデータ分析のためのSolr検索とSpark – Big Data Day LA 2015
ApacheのSolrは、データの対話的なビジュアライズとデータを探索とをとても簡単にします。ダッシュボードを作成し、いくつかのファセットを追加し、いくつかの値を選択し、時間で横断し、結果を見るだけです。Apache Sparkはストリーミング計算を実行するために成長しているフレームワークで、リアルタイムのインデキシングを理想的にします。Solrには、データ探索の兵器庫に追加された主要な武器である、新しい解析ファセットがあります。これらは別の次元、「計算」をもたらします。私たちは今、はるかに簡単かつ迅速な方法でSQLと同等のことができます。これらの計算は、データのバケット上で操作することができます。
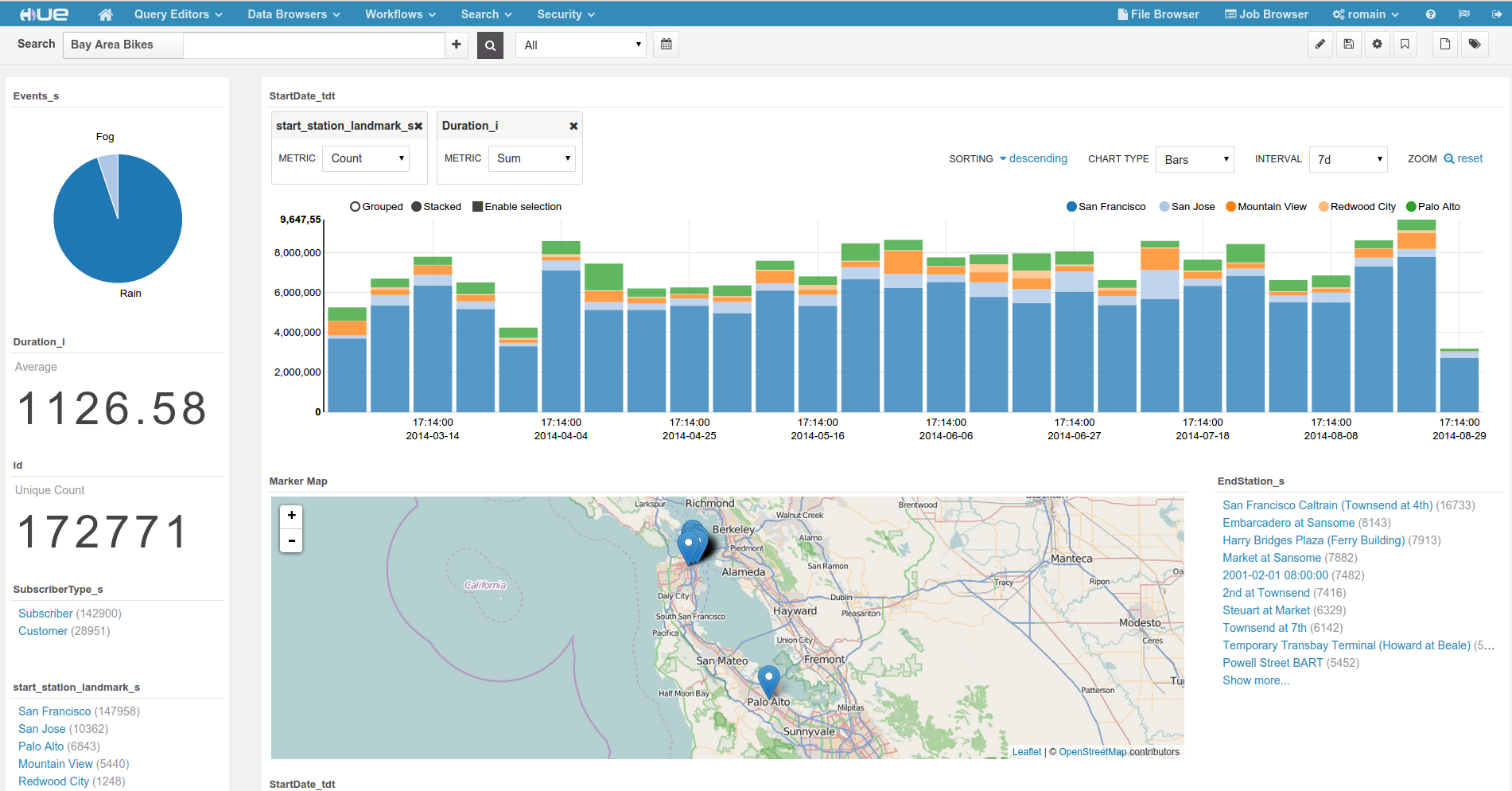
Bay Area Bikeからのデータ
ライブデモで使用した データの一部 をダウンロード