以前の記事で 、私たちはベイエリアの自転車の共有データから移動データをシームレスにインデックス化、視覚化し、ダッシュボードに気象データを追加して、分析を補足するためにSparkを使用する方法について説明しました。
このチュートリアルでは、ベイエリアの自転車の共有(BABS: Bay Area Bike Share)システムの、ピークの使用量をより深く研究するためにノートブックアプリを使用します。
http://www.bayareabikeshare.com/datachallengeから最新のデータセットをダウンロードします 。本記事では2014年2月から2013年8月までのデータを使用しています。
メタストアアプリでCSVデータをインポートする
BABSデータセットには、駅、移動、利用できるかどうか、および気象データを含む4つのCSVが含まれています。Hueのメタストアのインポートウィザードを使用して、これらのデータセットを簡単にインポートし、CSVのヘッダからスキーマを推測してテーブルを作成することができます。
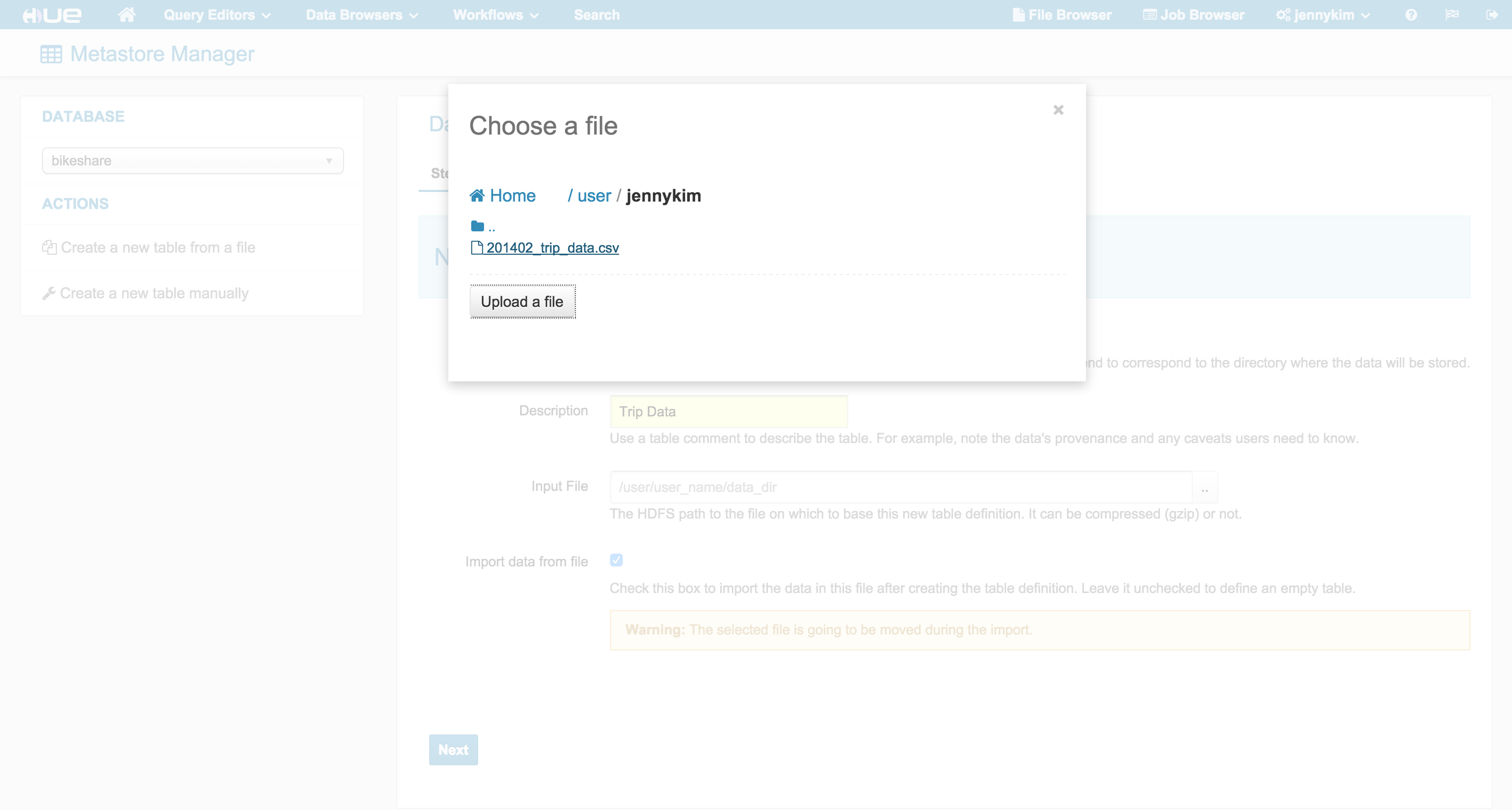
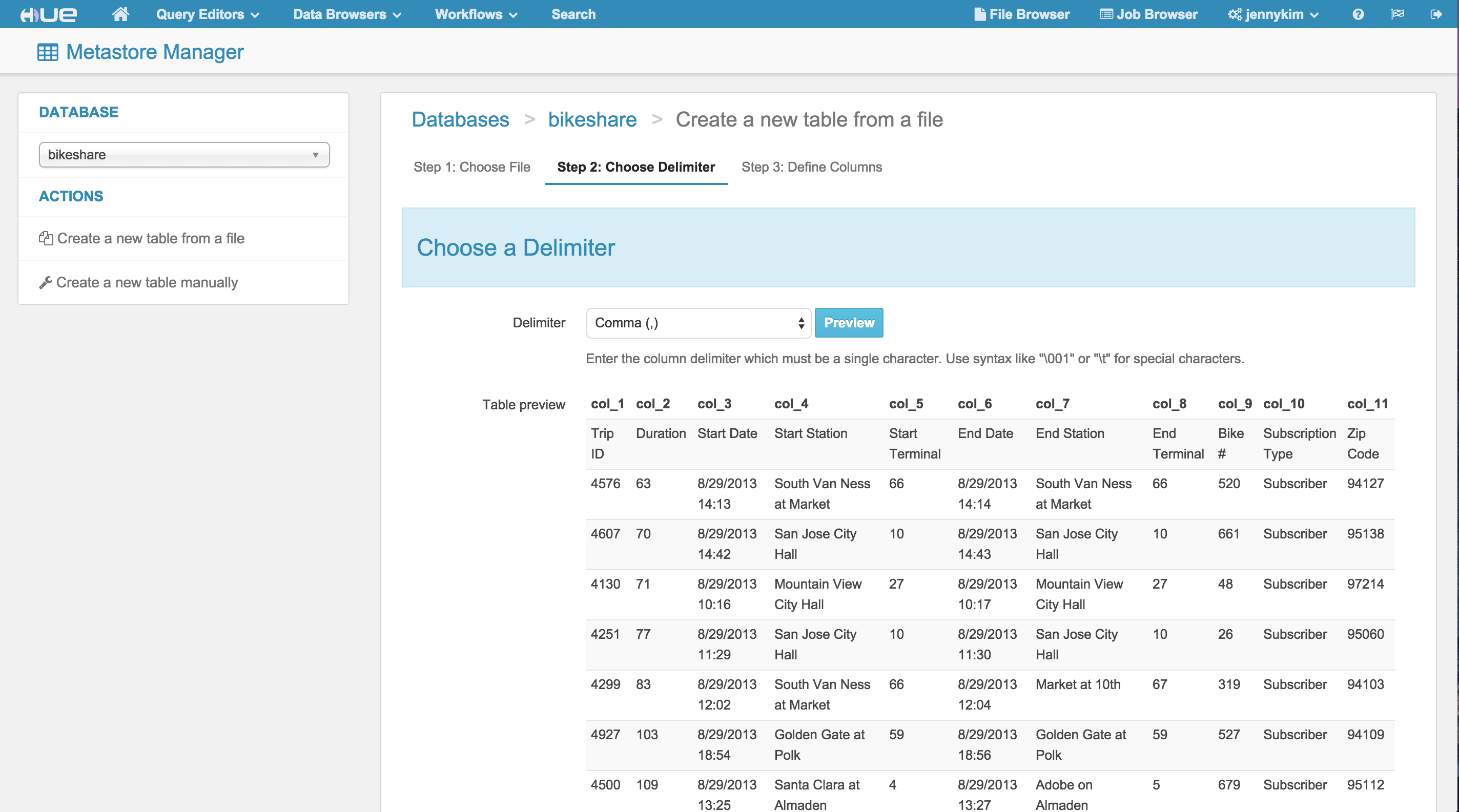
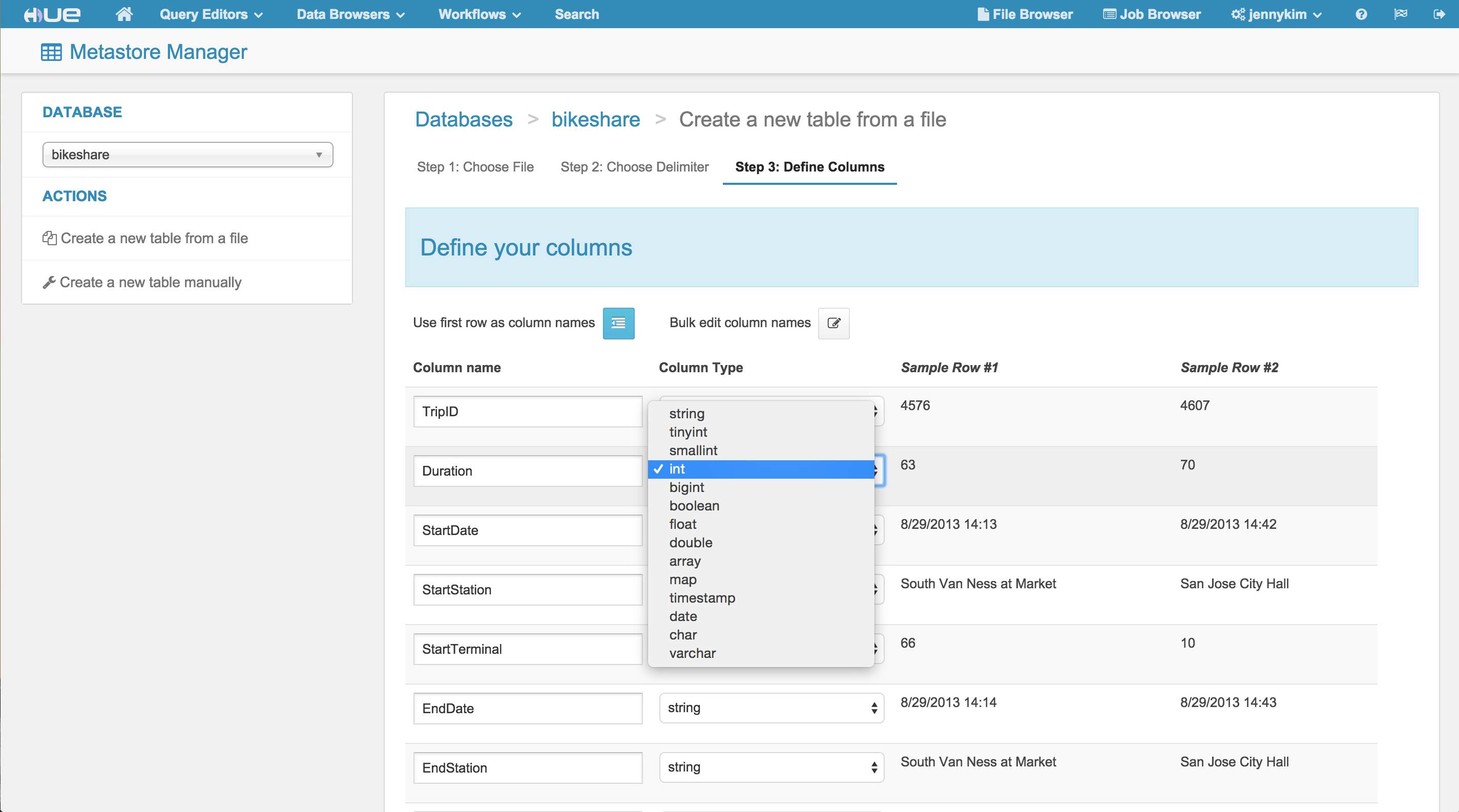
インポートウィザードは、移動データの「期間(duration)」フィールドを、TINYINTからINTに変更するような、任意のフィールド名や種類を上書きする機会を提供します。
Hadoopノートブックでの対話的な分析
電光石火のImpalaクエリ
私たちはクラスタにデータをインポートしているので、データの大量処理を実行するための新しいノートブックを作成することができます。始めるには、Impalaを使用していくつかの簡単な探索クエリを実行します。
移動データに基づいて、最も人気のある出発駅の上位10件を見つけてみましょう:
SELECT startterminal, startstation, COUNT(1) AS count FROM bikeshare.trips GROUP BY startterminal, startstation ORDER BY count DESC LIMIT 10
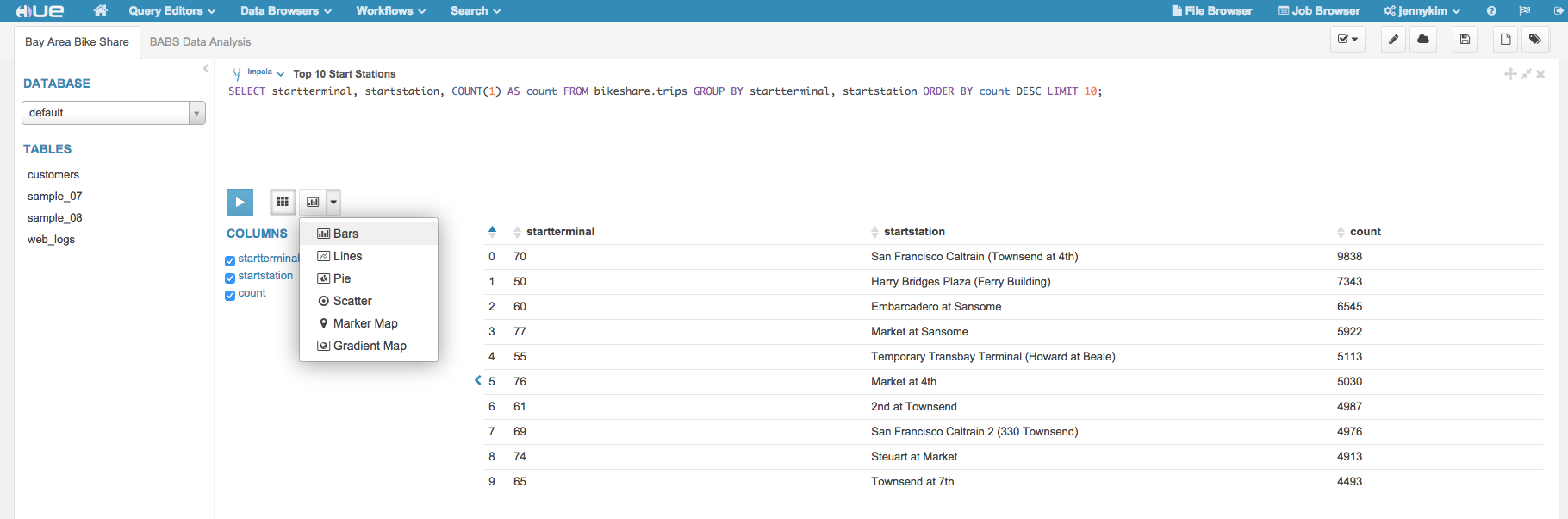
結果が返ってくれば、私たちはこのデータを簡単に可視化できます。棒グラフは簡単な COUNT … GROUP BY クエリでうまく動作します。

サンフランシスコのカルトレイン(Townsend at 4th: タウンセンド 4th)が最も一般的な出発駅だったようです。それでは、SFカルトレインのタウンゼント駅から出発する移動で、最も人気のあった終着駅はどこなのかを特定してみましょう。結果を地図上に可視化できるように緯度と経度の座標を取得します。
SELECT s.station_id, s.name, s.lat, s.long, COUNT(1) AS count FROM `bikeshare`.`trips` t JOIN `bikeshare`.`stations` s ON s.station_id = t.endterminal WHERE t.startterminal = 70 GROUP BY s.station_id, s.name, s.lat, s.long ORDER BY count DESC LIMIT 10
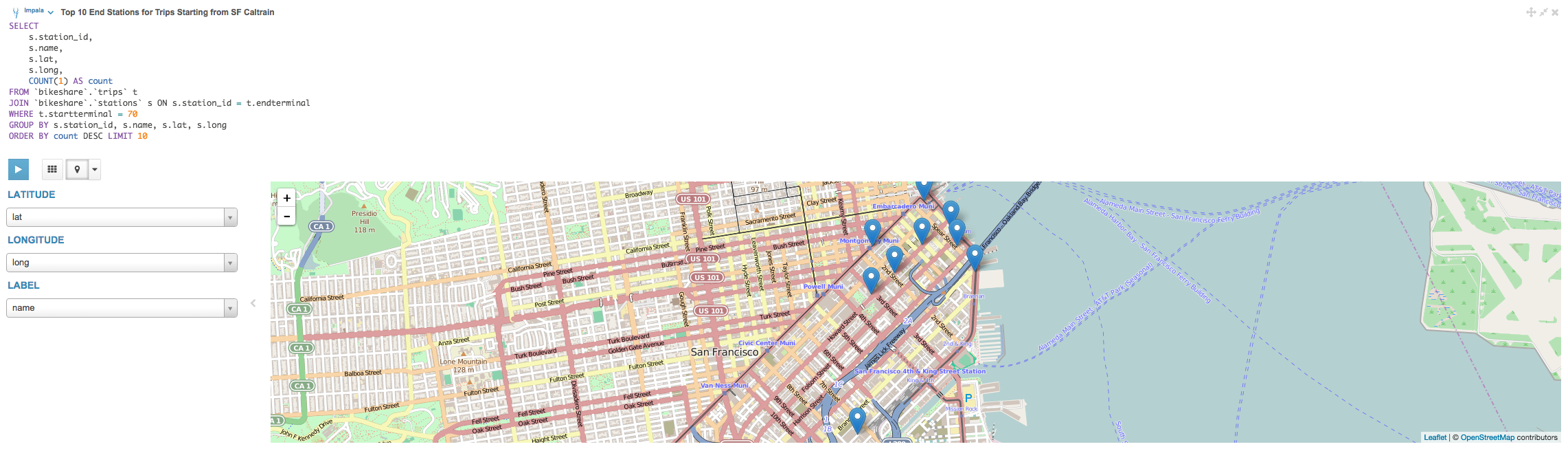
地図の可視化では、SFカルトレインの駅から出発する最もポピュラーな移動の目的地のほとんど駅にかなり近く、金融地区とSOMAの周りにクラスタ化されていることを示しています。
Hiveでの長時間実行するクエリ
長時間実行するSQLクエリ、またはHiveの組み込み関数を使用する必要があるクエリの場合、この分析を実行するために、ノートブックにHiveのスニペットを追加することができます。
Fカルトレイン駅の移動データをさらに掘り下げ、移動の合計数と、1時間単位でグループ化した移動の平均の時間(分)をみつけたいとしましょう。
移動データは出発時間をSTRINGとして保存しているので、インラインSQLクエリ内で時間を抽出するため、いくつかの文字列操作を適用する必要があります。外部のクエリで移動の回数と平均の期間を集約します。
SELECT
hour,
COUNT(1) AS trips,
ROUND(AVG(duration) / 60) AS avg_duration
FROM (
SELECT
CAST(SPLIT(SPLIT(t.startdate, ' ')[1], ':')[0] AS INT) AS hour,
t.duration AS duration
FROM `bikeshare`.`trips` t
WHERE
t.startterminal = 70
AND
t.duration IS NOT NULL
) r
GROUP BY hour
ORDER BY hour ASC;
このデータはデータのいくつかの数値の面を生成するので、X軸に時間、Y軸に移動の数、散布の大きさで平均の期間を、散布グラフを使用して結果を可視化することができます。それでは、SFカルトレイン駅で、時間ごとに利用できる内訳を分析するために、別のHiveのスニペットを追加してみましょう:

Let’s add another Hive snippet to analyze an hour-by-hour breakdown of availability at the SF Caltrain Station:
SELECT
hour,
ROUND(AVG(bikes_available)) AS avg_bikes,
ROUND(AVG(docks_available)) AS avg_docks
FROM (
SELECT
r.time AS time,
CAST(SUBSTR(r.time, 12, 2) AS INT) AS hour,
CAST(r.bikes_available AS INT) AS bikes_available,
CAST(r.docks_available AS INT) AS docks_available
FROM `bikeshare`.`rebalancing` r
JOIN `bikeshare`.`stations` s ON r.station_id = s.station_id
WHERE
r.station_id = 70
AND
SUBSTR(r.time, 15, 2) = '00'
) t
GROUP BY hour
ORDER BY hour ASC;
私たちは、自転車が利用できるのが午前6時から低下し、午後6時頃に回復している傾向があることを示す結果を、線グラフとして可視化します。

PySparkによる強力なデータ解析
ある時点で、あなたのデータ分析がSQLでのリレーショナルな分析の限界を超えるかもしれず、また、それ以上の表現力、本格的なAPIが必要になるかもしれません。
HueのSparkのノートブックは、ユーザーがカスタムのScala、Python (pyspark)、およびSpark APIを利用するRのコードで、調査のためのSQL分析を混在させることができます。
例えば、pysparkスニペットをオープンし、Hiveのwarehouseから直接旅行データをロードし、SFカルトレイン駅からスタートする旅行の平均数を特定するために、filter、map、およびreduceByKey操作のシーケンスを適用することができます:
trips = sc.textFile('/user/hive/warehouse/bikeshare.db/trips/201402_trip_data.csv')
trips = trips.map(lambda line: line.split(","))
station_70 = trips.filter(lambda x: x[4] == '70')
# Emit tuple of ((date, hour), 1)
trips_by_day_hour = station_70.map(lambda x: ((x[2].split()[0], x[2].split()[1].split(':')[0]), 1))
trips_by_day_hour = trips_by_day_hour.reduceByKey(lambda a, b: a+b)
# Emit tuple of (hour, count)
trips_by_hour = trips_by_day_hour.map(lambda x: (int(x[0][1]), x[1]))
avg_trips_by_hour = trips_by_hour.combineByKey( (lambda x: (x, 1)),
(lambda x, y: (x[0] + y, x[1] + 1)),
(lambda x, y: (x[0] + y[0], x[1] + y[1]))
)
avg_trips_by_hour = avg_trips_by_hour.mapValues(lambda v : v[0] / v[1])
avg_trips_sorted = sorted(avg_trips_by_hour.collect())
%table avg_trips_sorted
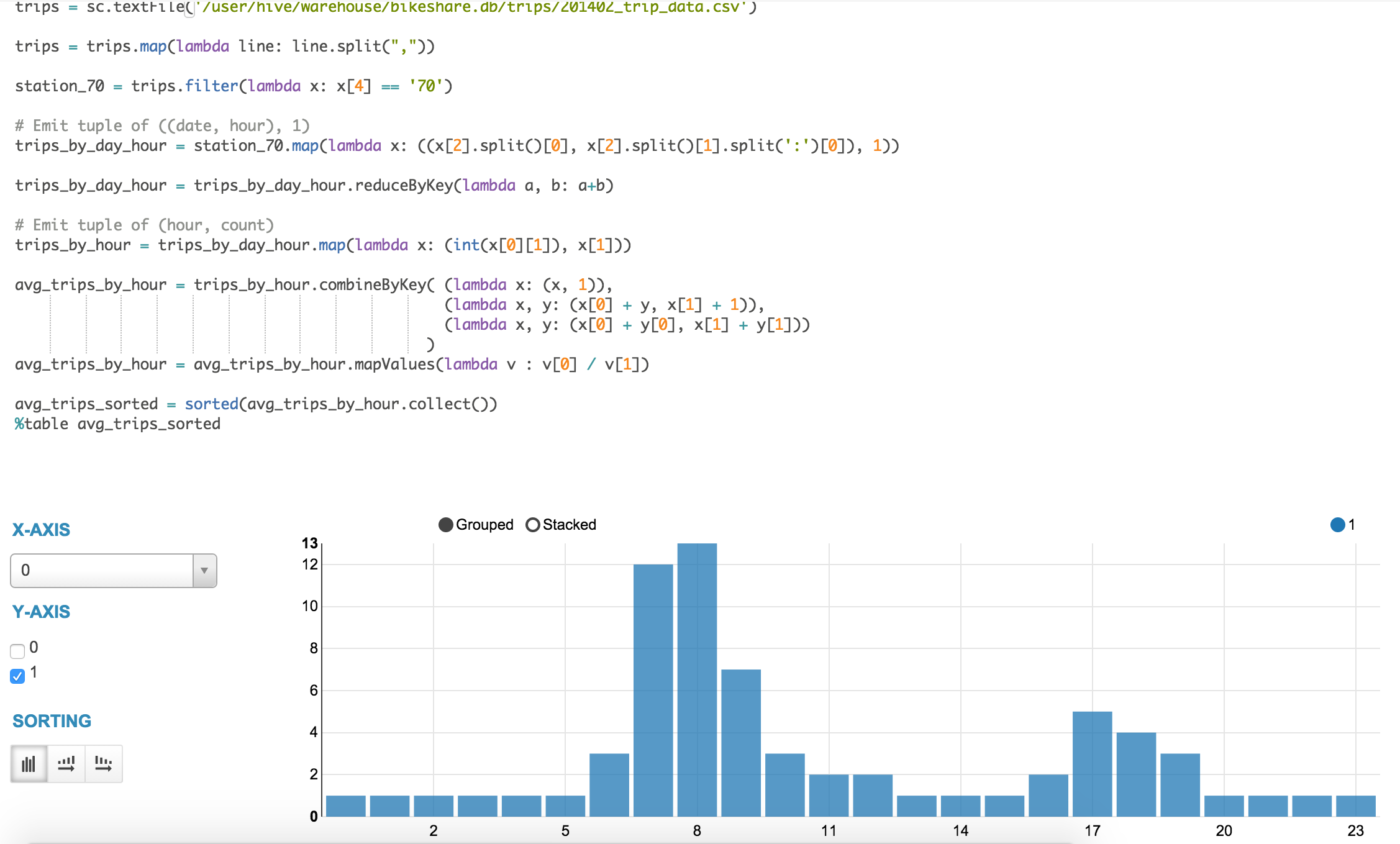
ご覧のように、Hueのノートブックアプリは、強力なツールを組み合わせ、簡単にインタラクティブなデータ分析と可視化ができるようになります。Sparkのノートブックの動作についてもっと知りたい方はLivy、Spark REST Job serverについてご覧いただき、ニューヨークのHadoop WorldとアムステルダムのSpark Summitでお会いしましょう!
ノートブックアプリへの数々の刺激的な改善をお楽しみに!そしていつものようにいつものように、コメントとフィードバックは hue-userメーリングリストや@gethueまでお気軽に!
役立つヒント
引用符のあるCSVデータのインポート
(201402_status_data.csvという名前の)BABSの利用可能性(リバランス)データは引用符を使用しています。このような場合は、BeeswaxエディタでHive内にテーブルを作成し、HiveのOpenCSV Row SERDEを使用するのが簡単です:
CREATE TABLE rebalancing(station_id int, bikes_available int, docks_available int, time string) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = """, "escapeChar" = "\" ) STORED AS TEXTFILE;
その後、テーブルにCSVファイルをインポートするためにメタストアに戻ることができます。手作業でヘッダー行を削除する必要があることに注意してください。
Impalaのメタストアのキャッシュをリセットする
新しいデータベースやテーブルを作成したり、Impalaのスニペットでそれらのクエリを計画している場合は、INVALIDATE METADATA、最初にメタストアのキャッシュをリセットするコマンドの実行をお勧めします。そうしないと、データベースやテーブルが認識されないというエラーが発生することがあります。