私たちは、最近、1クリックで実際のHadoopクラスタを試すことができるdemo.cloudera.comを開始しました。下記は私たちがそれをどのように行ったかについて書いたものです。
始める前に、あなたは何台かのマシンを入手する必要があります。Hadoopはコモディティハードウェアで実行されるので、メジャーなLinuxディストリビューションが動く普通のコンピュータで動作するはずです。デモを続けるために、Amazon Cloud Computing Serviceをちょっと見てみましょう。既にサーバーを1〜2台に持っている、あるいはローカルのLinuxマシンでHadoopを実行することなど気にしない場合は、そのままマシンのセットアップを行って下さい!
これは、クラスタをブートし、データの演算を始めるのがいかに簡単であることかを示しているデモンストレーションビデオです!
マシンのセットアップ
私たちは AWS を選んで、OSにはUbuntu 12.04、100GBのストレージを持つ4つのm3.large インスタンスを開始しました(デフォルトの8GBではなく)。低いパフォーマンスで良い場合は、一つのxlargeインスタンスで十分であり、またはさらに小さなインスタンスに少ないサービスをインストールすることができます。
続いて以下のようにセキュリティグループを設定します。私たちはインスタンス間で全てを許可し(複数のマシンのクラスタであることを忘れないで下さい!)、外部にCloudera ManagerとHueのポートを解放しました。
|
All TCP |
Hadoopのセットアップ
この時点で私たちは既に複数のマシンを手にしているので、Hadoopをインストールしましょう。私たちは全てのインストールにCloudera Managerを使用して、このガイド(英語)に従いました。さらには、インストール後のモニタリングと設定も、管理インタフェースにより簡易化されています。
最初にマシンの一つに接続することから始めます:
ssh -i ~/demo.pem [email protected]Cloudera Managerを取得して開始します:
wget http://archive.cloudera.com/cm5/installer/latest/cloudera-manager-installer.bin
chmod +x ./cloudera-manager.bin
sudo ./cloudera-manager.binデフォルトの資格である admin/admin でログインします。
その後、インストールウィザードであなたのマシンの全てのパブリック DNS IP(例: ec2-11-222-333-444.compute-1.amazonaws.com) を入力し、Go!をクリックします。おめでとうございます。あなたのために、Cloudera Managerがクラスタ全体を自動的にセットアップしてくれるでしょう!
dynamic IPをHueのマシンに割り当ててそのIPアドレスのポート番号8888にアクセスします。完全に機能しているHadoop クラスタでチュートリアル(英語)とサンプル(英語)を始めましょう!
いつものように、hue-user メーリングリスト、または @gethueまでお気軽にコメントして下さい!
注意
あなたが複数のマシンを持っている場合、メモリ/CPUの使用量が均一になるようにサービスを異動することを推奨します。例えば、HBase、Oozie、Hive、Solrを異なるホストに分けるようにします。
注意
YARNでいくつかのMapReduceジョブを実行する際、全てのジョブがACCEPTEDあるいはREADYステータスでデッドロックする場合、YARNのバグにヒットしているかもしれません。
回避方法は、2〜3ぐらいの少ない数の動的リソース管理プール(Dynamic Resource manager Pool)を使用することです。 CM → Clusters → Other → Dynamic Resource Pools → Configuration → Edit → YARNに異動し、‘Max Running Apps’ を2に設定します。
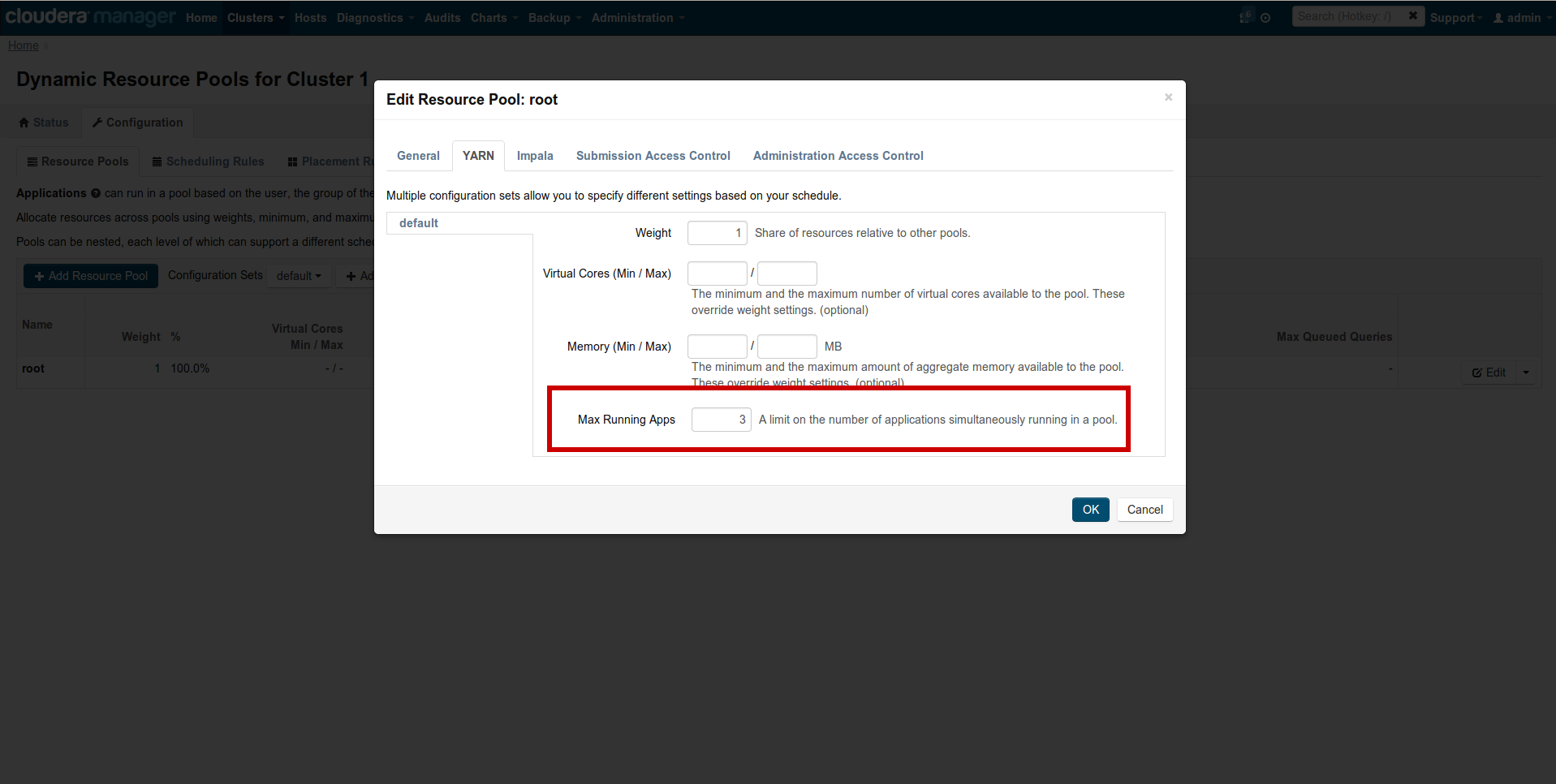
同様に、yarn.nodemanager.resource.memory-mbとタスクのメモリを減らし、yarn.app.mapreduce.am.resource.mbを増やしてみることもできます。